
<< Building Views with IBM Engineering Lifecycle Optimization – Engineering Insights (ENI) Part One – Introduction
In this article, we’ll build our first view. Later we’ll make it look visually appealing and introduce some dynamic visualization but we’ll start by simply reporting the data we are interested in and see just how quickly and easily views can be designed. We’ll be building this view using the out-of-the-box sample data that ships with ELM – JKE Banking (or whatever you choose to call it when you deploy it). That sample just happens to be a finance sample, but it has the same kinds of an artifact that IT and Engineering projects have, it has requirements, it has test cases and it has work items.
Conceptual Roles
ENI has three conceptual roles (these are not tool-based roles that appear in the UI)
- Consumers: Project managers, engineers and so on that simply want to view the graphical analyses, typically on dashboards. Consumers need very little knowledge of ENI (only perhaps how to modify the parameters a view designer has included to allow dynamic customization of the returned data)
- View Designers: As the name implies, designers build the views that the consumers use. Designers need to know (a) how to use the tool to build views and (b) the information model. How is the data being created? What link types are being used? How many levels of traceability have been implemented? What kinds of analyses are required?
- Custom Artifact Element Designers: This is the deepest level of customization and requires all the knowledge of a View Designer but also the concepts of RDF and the SPARQL query language.
For most of this series, we will flip back and forth between Consumers and View Designers. A later series of articles will focus on the concepts around Custom Artifact Elements, how they are used and how they are designed.
Building a View
Creating the Project
One of the major differences between an ENI project and any other Jazz-based project is that it does not scope the visible data. As we discussed in the previous article, ENI sits on top of LQE and LQE sees all. The visible data is only scoped by (a) the users’ permissions to see the data and (b) the scoping that the View Designer decides to apply and this is done in the View – not at a project level.
Creating a View
Creating a new View is an exercise in simplicity; there are multiple menu items and indicated buttons to do so.

Your new View can be created in the Shared section and thus instantly available to anyone else who is a member of this ENI project; or it can be in the My Views section, visible only to you (until you choose to move it).
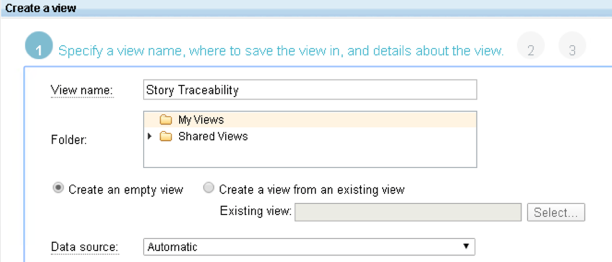
When you create the view, you can if you wish to limit its scope immediately to only specific projects. You don’t have to do that; you can add project-level filtering later, in containers or links (you’ll see that later). My recommendation is this: don’t limit it until you have to / want to, so we can skip this page (selecting nothing means we don’t want to apply any project filtering)
Populating a View
Views are populated by dragging elements from the palette onto the canvas:
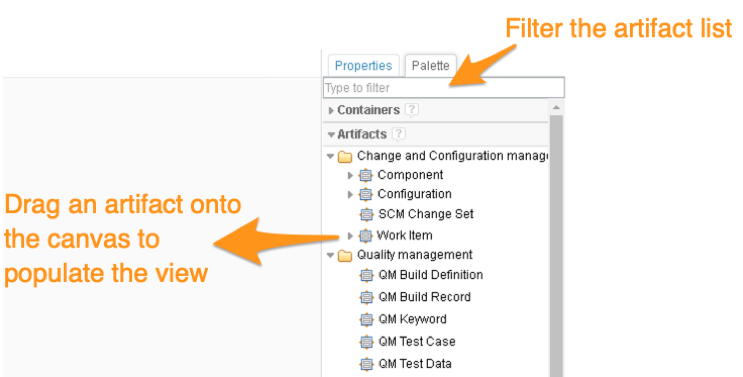
Artifacts and Custom Artifact Elements
It’s worth at this point acknowledging that the palette has three sections:
- Containers
- Artifacts
- Custom Artifact Elements
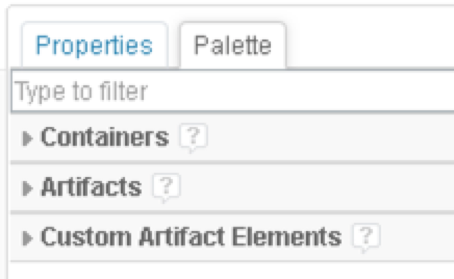
Leaving Containers aside for a moment, the two major sections are Artifacts and Custom Artifact Elements. Both represent “stuff” in your database. For example, work items, test cases, requirements and so on. However, they have some key differences:
- Artifacts
- Are populated automatically by ENI by asking the data source ‘hey – what do you have ?’
- Custom work item types, requirement attributes and so on all appear automatically with no effort at all on your part
- They are limited to what the data source returns (more on this later)
- Custom Artifact Elements
- Do not appear automatically. They have to be hand-crafted using a query language called SPARQL (although a sample set can be deployed)
- Are more flexible than Artifact Elements; you can write a query to interrogate the data source in any way you like.
For this first set of articles, we’ll use the automatically-generated Artifacts. Since the sample data has a work item type called Story, we can drag that Artifact onto our canvas:
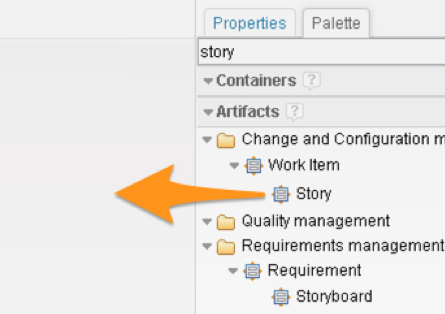
Refining Container Content
When an Artifact is dragged onto the canvas, it turns into a container. That container will be populated with graphical nodes that represent the data source, in this case, Stories. Before that happens, we can choose to filter that population in several ways; by the project (Edit scope tab); by the presence of outgoing links (Link types tab); or by any attribute of the data source (Edit conditions tab).
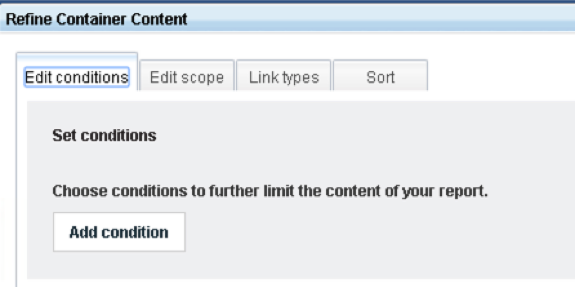
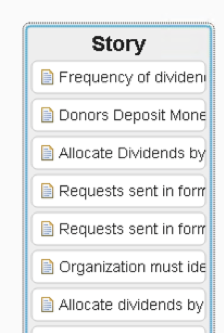
This is optional and we can invoke the same dialog later so, for now, we can click OK to see All Stories:
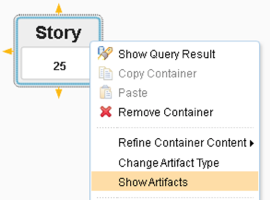
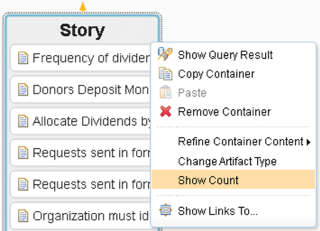
Showing a Count
Using the right-click menu for a container we can toggle it between showing the artifacts or a count of those artifacts:

Adding Connected Artifacts
If the container is showing artifacts (not a count) then we can add a new container that populates with connected artifacts by right-clicking the existing container (in this case Story) and selecting the menu Show Links To:
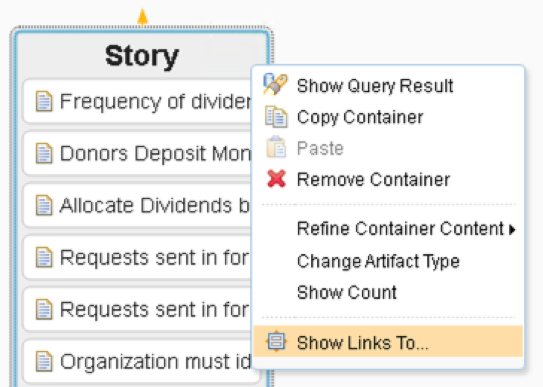
This starts a wizard with several pages where we can:
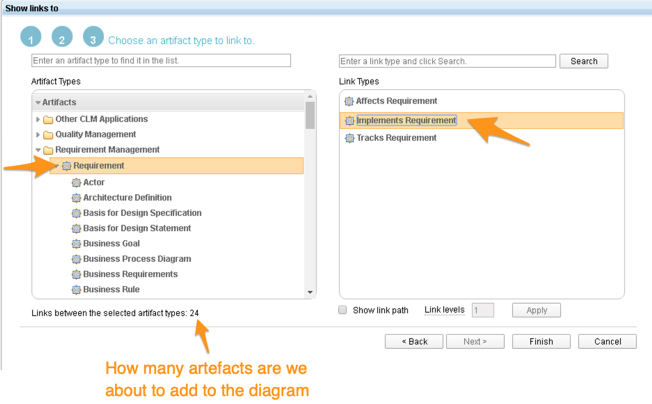
- Create a new container or add connections to an existing one (in this case we are creating a new container)
- Filter by the project (useful if our Stories connected to artifacts in multiple projects – they don’t so we can skip this page)
- Select the type of artifact and the type of link we want to use to populate the new container:

We can continue adding more containers to show whatever traceability we want. This is where the information model becomes important!

Filtering a Container
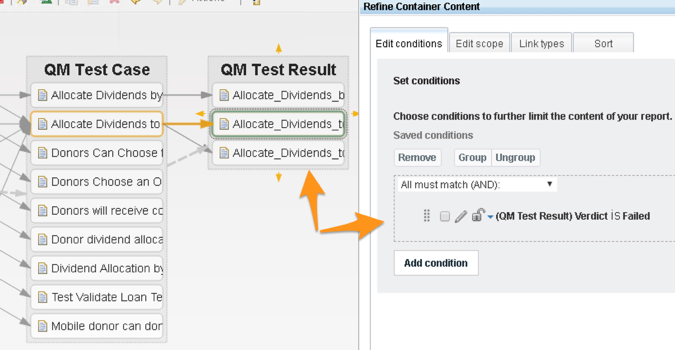
Remember when we first dragged the Story artifact onto the view and we had a chance to apply to filter? Let’s invoke that again. We can right-click any container (in this case we’ll right-click the Story container) and select Refine Container Content > Edit conditions.
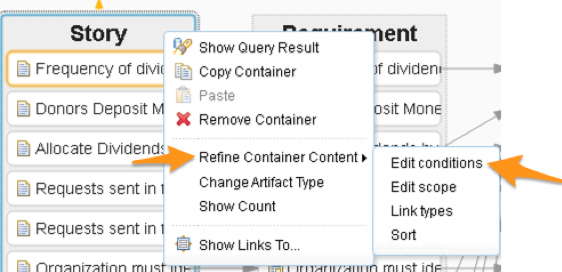
It doesn’t matter which of that four sub-menus we choose since they all invoke the same dialog that has those menu entries as tabs.
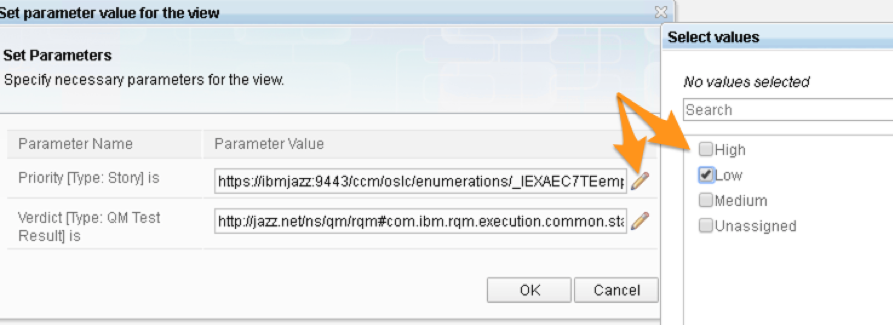
On the Edit conditions tab, we can filter the container based on any of the data source attributes. For example, we could filter based on the Priority of the Story:
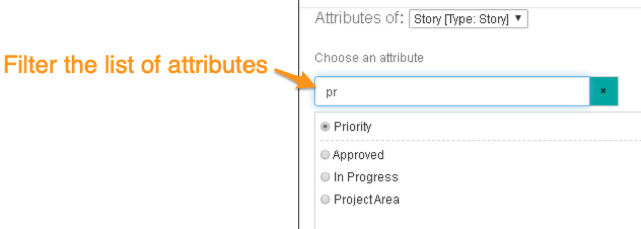
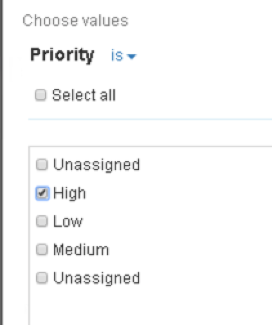
We can also decide if the Consumer of the view can change the condition to see different data (the default is yes, they can – but they don’t have to)

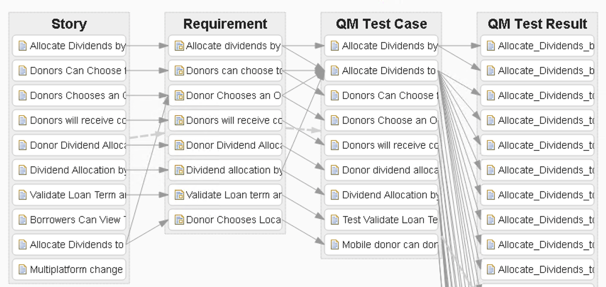
We can apply filters to any of the containers, not just the first one:
Consuming the View
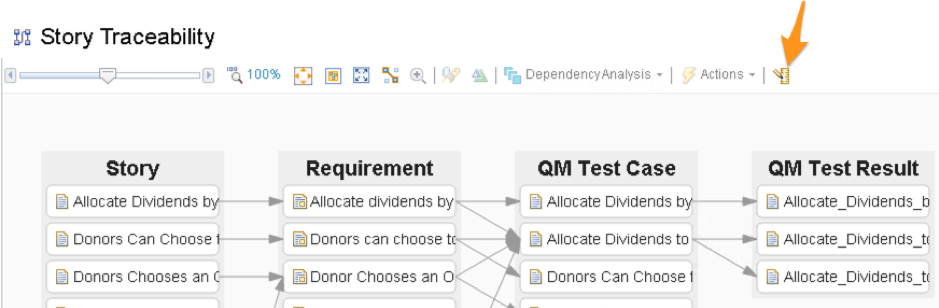
By clicking Save and Close we can switch from designing the View to consuming it (of course the View appears on the menus and can also be added directly to dashboards in other parts of the platform). To change the filter values, we click the ‘ruler’ symbol in the tools bar:
Creating an Impact Analysis Style View
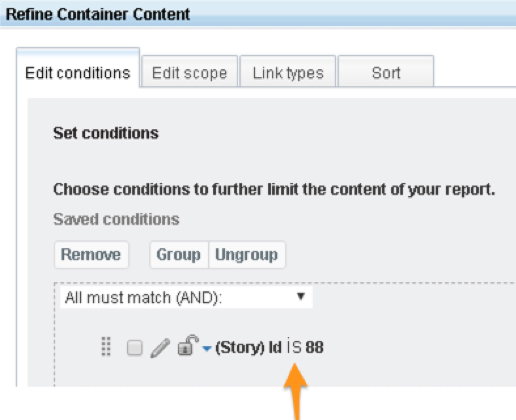
These types of views typically start with a single artifact. We can implement that easily by applying a filter to our starting container that only returns a single artifact. ID or URL are both good choices:
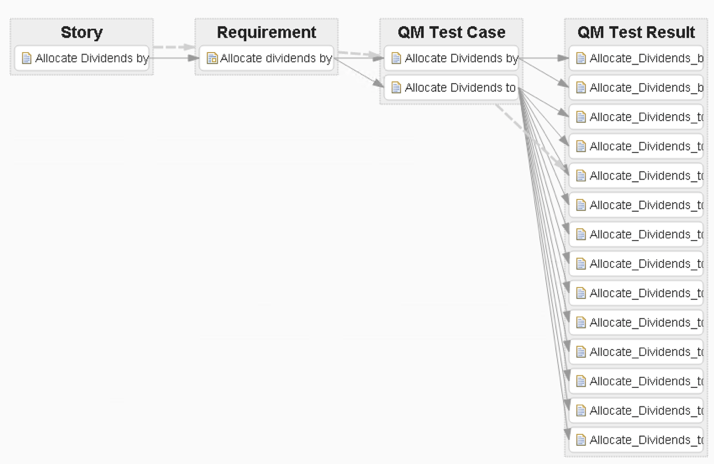
That’s all for now; later we’ll see how to make this view dynamic so that the Consumer of the view can easily select a Story with a single click and instantly see the traceability view change. We’ll also see how we can make the view more visually appealing by changing the colors, line shapes and so on.
Building Views with IBM Engineering Lifecycle Optimization – Engineering Insights (ENI) Part Three – Customizing the Look and Feel of Views (The Basics) >>
Andy Lapping
Technical Enablement Specialist
Watson IoT & Engineering Lifecycle Management
 (1 votes, average: 5.00 out of 5)
(1 votes, average: 5.00 out of 5)Authors
 Adam Archer (1)
Adam Archer (1) Adam Neal (1)
Adam Neal (1) Adrian Cho (15)
Adrian Cho (15) Alice Connors (3)
Alice Connors (3) Amy Silberbauer (24)
Amy Silberbauer (24) Andrew Hans (1)
Andrew Hans (1)- Andy Lapping (15)
 Anindita Basu (3)
Anindita Basu (3) Anthony Hunter (1)
Anthony Hunter (1) Benjamin Pasero (5)
Benjamin Pasero (5) Benjamin Williams (3)
Benjamin Williams (3) Bernie Coyne (6)
Bernie Coyne (6) Beth Zukowsky (2)
Beth Zukowsky (2) Bhawana Gupta (9)
Bhawana Gupta (9) Bianca Jiang (3)
Bianca Jiang (3) Bill Higgins (2)
Bill Higgins (2) Boris Kuschel (2)
Boris Kuschel (2) Brent Barkman (2)
Brent Barkman (2) Brian Bryson (1)
Brian Bryson (1) Brian King (4)
Brian King (4) Brian Lang (2)
Brian Lang (2) Brian Massey (3)
Brian Massey (3) Brian Sanders (2)
Brian Sanders (2) Bruce MacIsaac (2)
Bruce MacIsaac (2) Carlos Ferreira (1)
Carlos Ferreira (1) Carolyn Pampino (10)
Carolyn Pampino (10) Catherine Burrows (1)
Catherine Burrows (1) Chandra Venkatapathy (1)
Chandra Venkatapathy (1) Chris Daly (1)
Chris Daly (1) Chris Trobridge (1)
Chris Trobridge (1) Christophe Cornu (3)
Christophe Cornu (3) Christophe Elek (5)
Christophe Elek (5) Christophe Telep (14)
Christophe Telep (14) Clara Forero (1)
Clara Forero (1) Clare Carty (4)
Clare Carty (4) Dan Barbour (1)
Dan Barbour (1) Dan Griffin (5)
Dan Griffin (5) Dan Leroux (2)
Dan Leroux (2) Daniel Berg (2)
Daniel Berg (2) Daniel Moul (25)
Daniel Moul (25) Daniel Toczala (4)
Daniel Toczala (4) Darin Swanson (1)
Darin Swanson (1) Darrel Rader (1)
Darrel Rader (1) Dave Thomson (7)
Dave Thomson (7) David Brauneis (1)
David Brauneis (1) David Hodges (1)
David Hodges (1) Dejan Glozic (2)
Dejan Glozic (2) Denise Cook (1)
Denise Cook (1) Derek Baron (8)
Derek Baron (8) Dibbe Edwards (3)
Dibbe Edwards (3) Dirk Baeumer (1)
Dirk Baeumer (1) Don Yantzi (1)
Don Yantzi (1) Doron Ben-Ari (3)
Doron Ben-Ari (3) ELM Engineering (42)
ELM Engineering (42) Eran Gery (1)
Eran Gery (1) Erich Gamma (5)
Erich Gamma (5) Erik Craig (1)
Erik Craig (1) Ernest Mah (1)
Ernest Mah (1) Evan Hughes (3)
Evan Hughes (3) Fariz Saracevic (16)
Fariz Saracevic (16) Frederic Fusier (1)
Frederic Fusier (1) Gary Cernosek (1)
Gary Cernosek (1) George DeCandio (4)
George DeCandio (4) Gili Mendel (1)
Gili Mendel (1) Ginny Ghezzo (1)
Ginny Ghezzo (1) Graham Bleakley (5)
Graham Bleakley (5) Grant Covell (1)
Grant Covell (1) Greg Gorman (1)
Greg Gorman (1) Guy Slade (1)
Guy Slade (1) Hadar Hawk (2)
Hadar Hawk (2) Heidi Stadel (1)
Heidi Stadel (1) James Branigan (2)
James Branigan (2) James Moody (2)
James Moody (2) Jan Wloka (2)
Jan Wloka (2) Jared Pulham (7)
Jared Pulham (7) Jean-Michel Lemieux (23)
Jean-Michel Lemieux (23) Jeanette Deupree (1)
Jeanette Deupree (1) Jim Amsden (1)
Jim Amsden (1) Jim D'Anjou (2)
Jim D'Anjou (2) Jim Ruehlin (1)
Jim Ruehlin (1) Johannes Rieken (2)
Johannes Rieken (2) John Kellerman (2)
John Kellerman (2) John Vasta (1)
John Vasta (1) John Whitfield (2)
John Whitfield (2) John Wiegand (1)
John Wiegand (1) Jozef deVries (1)
Jozef deVries (1) Kai-Uwe Maetzel (6)
Kai-Uwe Maetzel (6) Kalena Kelly (1)
Kalena Kelly (1) Karen Gosciminski (1)
Karen Gosciminski (1) Kate Draper (2)
Kate Draper (2) Kate Hauser (1)
Kate Hauser (1) Kevin Williams (2)
Kevin Williams (2) Kim Peter (10)
Kim Peter (10) Kiran M N (1)
Kiran M N (1) Kit Lo (1)
Kit Lo (1) Kourken Aroyan (1)
Kourken Aroyan (1) Kumaraswamy Gowda (15)
Kumaraswamy Gowda (15) Lauren Hayward Schaefer (15)
Lauren Hayward Schaefer (15) Lawrence Mandel (2)
Lawrence Mandel (2) Linda Watson (3)
Linda Watson (3) Liz Bonesteel (1)
Liz Bonesteel (1) Luc Hatlestad (1)
Luc Hatlestad (1) Lucinio Santos (1)
Lucinio Santos (1) Maneesh Mehra (3)
Maneesh Mehra (3) Manoj Panda (1)
Manoj Panda (1) Mario Maldari (1)
Mario Maldari (1) Mark Guertin (2)
Mark Guertin (2) Martha Andrews (3)
Martha Andrews (3) Mary Yost (1)
Mary Yost (1) Masabumi Koinuma (1)
Masabumi Koinuma (1) Mats Gothe (1)
Mats Gothe (1) Matt Lavin (1)
Matt Lavin (1) Michael Fiedler (1)
Michael Fiedler (1) Michael Halder (2)
Michael Halder (2) Michael Valenta (3)
Michael Valenta (3) Millard Ellingsworth (3)
Millard Ellingsworth (3) Miran Badzak (1)
Miran Badzak (1) Monica Luke (5)
Monica Luke (5) Moshe Cohen (1)
Moshe Cohen (1) Nadra Rafee (1)
Nadra Rafee (1) Nathan Bak (5)
Nathan Bak (5) Neil Leblanc (3)
Neil Leblanc (3) Nick Crossley (3)
Nick Crossley (3) Nithya Rajagopalan (3)
Nithya Rajagopalan (3) Palak Sheth (1)
Palak Sheth (1) Patrick Streule (1)
Patrick Streule (1) Paul Ellis (1)
Paul Ellis (1) Paul Strachan (1)
Paul Strachan (1) Paul Tasillo (2)
Paul Tasillo (2) Peter Haumer (1)
Peter Haumer (1) Peter Steinfeld (1)
Peter Steinfeld (1) Phil Vogel (3)
Phil Vogel (3) Priyadarshini Gorur (3)
Priyadarshini Gorur (3) Rahul Choudhary (4)
Rahul Choudhary (4) Reuben Varzea (12)
Reuben Varzea (12) Richard Bone (3)
Richard Bone (3) Richard Watson (13)
Richard Watson (13) Rishikesh Agam (2)
Rishikesh Agam (2) Robbie Minshall (1)
Robbie Minshall (1) Robin Bater (5)
Robin Bater (5) Roger LeBlanc (1)
Roger LeBlanc (1) Rolf Nelson (16)
Rolf Nelson (16) Rosa Naranjo (1)
Rosa Naranjo (1) Rosalind Radcliffe (1)
Rosalind Radcliffe (1) Ryan Manwiller (4)
Ryan Manwiller (4) Sandeep Kohli (1)
Sandeep Kohli (1) Sandeep Somavarapu (1)
Sandeep Somavarapu (1) Sanjesh Nair (1)
Sanjesh Nair (1) Scott Rich (13)
Scott Rich (13) Sean Babineau (1)
Sean Babineau (1) Seth Packham (11)
Seth Packham (11) Sharoon Shetty Kuriyala (1)
Sharoon Shetty Kuriyala (1) Sreerupa Sen (5)
Sreerupa Sen (5) Sridevi Sangaiah (1)
Sridevi Sangaiah (1) Steve DiCamillo (2)
Steve DiCamillo (2) Steven Beard (1)
Steven Beard (1) Subramanya Pilar (6)
Subramanya Pilar (6) Sujan Surendrananitha (2)
Sujan Surendrananitha (2) Suneel Santharam (2)
Suneel Santharam (2) Susan Yeshin (1)
Susan Yeshin (1) Tim Feeney (6)
Tim Feeney (6) Tod Creasey (1)
Tod Creasey (1) Tom Hollowell (4)
Tom Hollowell (4) Ubaidu Peediakkal (3)
Ubaidu Peediakkal (3) Vaibhav Srivastava (1)
Vaibhav Srivastava (1) Vandana Shenoy (1)
Vandana Shenoy (1) Vatsalkumar Parmar (1)
Vatsalkumar Parmar (1) Virginia Lovering (1)
Virginia Lovering (1) Will Streit (1)
Will Streit (1)
You must be logged in to post a comment.