
This is a quick overview of very recent efforts within the IBM Rational development organization to employ cloud technology coupled with aggressive provisioning, product install and configuration automation to improve and streamline our product System Integration test processes with an eye towards Continuous Delivery.
Motivation and challenges
Its a common story for sure but our product delivery teams here at IBM Rational are very keen to constantly improve product quality. They are also committed to shorter and shorter product cycles … essentially wanting to create, evolve and deliver our products faster and with increasing product quality. Piece O’ cake, right? Nope.
Our system verification and integration testing is central to overall product quality and requires install, configuration and and test-scenario execution of our products on a huge variety of OS platforms, databases and physical topologies with large numbers of internal and third-party integrations.
When we started down this path to shorter development cycles we were primarily installing and configuring test systems by hand on physical hardware. This was doable given our traditional long product cycle. However, we saw ourselves quickly approaching a very hard wall when asked to support shorter cycles. This meant that, instead of going through this complex system provision, install, configure and scenario test cycle by hand x times a year, we would have to do it 2x times a year, then 4x, etc. We needed to change our way of doing things drastically … and soon.
Our gamble centered on two key themes: Golden Topologies and Cloud-based systems coupled with install and configuration automation. The Golden Topology approach enables us to focus on a finite set of test systems out of the, essentially, infinite combinations possible within our set of supported platforms, databases, integrations, etc. The rest of this post will describe our approach to cloud-based delivery of ready-to-test systems and we will provide another article focused on our Golden Topology strategy in the near future.
Summary of implementation
When we began this effort we had been driving two proof-of-concept (POC) private cloud systems and each allowed self-provisioning of test systems. The first of these two systems could provide one or more independent VMs to be deployed at which point Rational Build Forge was employed to orchestrate the execution of scripts to deploy products under test and then stitch the VMs into a coherent system.
The second POC private cloud was based on IBM Workload Deployer (IWD). This ended up our preferred cloud implementation for two reasons: first, IWD supports the concept of virtual system patterns (VSPs). A VSP can be considered a template for a logical set of VMs with relationships between them. With a VSP defined you can deploy the system of needed VMs in one operation. Secondly, orchestration and automation code can be directly attached to the VSP (in the form of script packages) and when this code executes as part of deployment it has topology metadata directly available. These capabilities allow us to provide one-stop, push button deployment of very complex system topologies.
I’ll provide a quick example of a moderately complex topology we use to system test our Rational CLM product suite. If you are not familiar, CLM (Collaborative Lifecycle Management) is a solution we deliver as a single composite product that consists of Rational Team Concert (RTC), Rational Quality Manager (RQM) and Rational Requirements Composer (RRC). One of the Golden Topologies we employ to test CLM is a fully distributed, enterprise-class topology on Linux with DB2 as the Database and WebSphere as the application server and IHS as a reverse proxy. This is also affectionately referred to as “E1”.
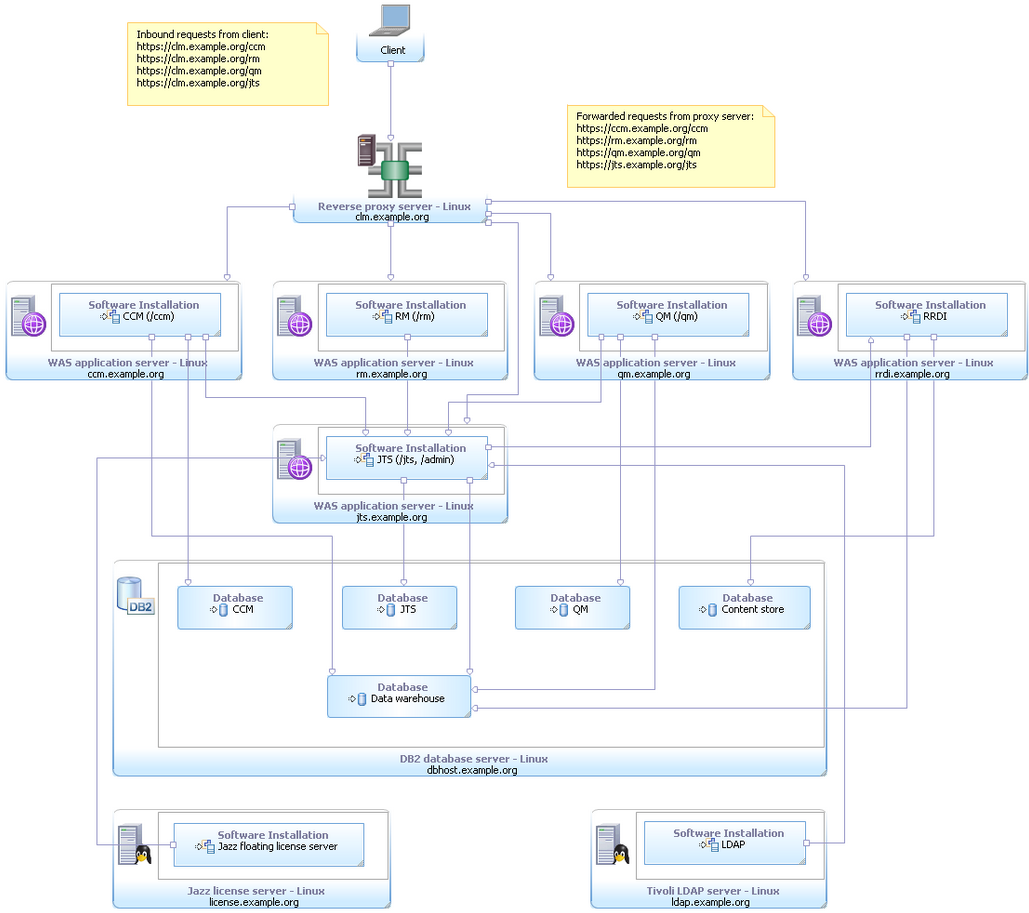
This topology employs a separate VM for each of the three CLM applications (CCM, RQM and RRC) and another for the shared Jazz Team Server (JTS). An additional VM is dedicated to the reverse proxy and yet another is reserved for DB2. To set up and configure this topology by hand and then install all products and configure them to work together with a common JTS and DB server is quite an undertaking even for a seasoned software engineer.
With VSPs we can take that seasoned engineer’s ability to configure such a system and burn it into automation for anyone to use. With this VSP, any team member can push a few buttons to self provision their own instance of E1!
Results and return on investment
When we started releasing this capability to our test teams the uptake was huge and immediate. This introduced a series of brand new problems around system capacity management that we can talk about in another post.
We immediately felt as if this capability was improving our ability to produce stable test systems more rapidly and with far fewer set-up and configuration errors. Being engineers we decided to define some metrics and start measuring
What we found was pretty amazing. For example, one of our more complex test system topologies for CLM is a horizontal WebSphere cluster with Oracle as the backend and WebSphere Proxy Server out front. This is, of course, is “E3”!. We surveyed some internal teams to get a sense of the time required to manually set up such a system from scratch. This is what we found:
|
Time to provision, Install/configure E3
|
|
|
Expert User
|
11 hours
|
|
Novice User
|
30 hours*
|
|
Non-experienced User
|
96 hours*
|
*note – these novice and non-experienced users will inevitably be stealing cycles from the experts.
|
Average User
|
42 hours
|
So assume an average time per manual deployment of 42 hours. Now consider that any user: expert, novice or zero experience can deploy the same stable system in about 3 hours total using a VSP. Also consider it takes the user five minutes to launch the VSP deployment process. The next 2 hours and 55 minutes can be spent doing something constructive while waiting for the system to become available.
When we’re talking about short development cycles where these deployments are needed in rapid succession the savings add up fast. At a savings of 40 hours per system deployment within the context of short development cycles you’re into savings measured in person-years very quickly. For example, here’s a quick business value assessment of patterns of similar complexity to our clustered pattern:
Let’s assume four teams (RTC, RQM, RRC, and the CLM) working concurrently and deploying a new system for each of three test topologies four times a month for one year.
Four deployments per month for four teams for three topologies for one year:
4 x 4 x 3 x 12 = 576 deployments
576 x 40 = 23,040 hours
23,040 / 2080 ~= 11 FTEs
This represents a fairly conservative estimate of savings we have realized for just three patterns. The return on investment is even more impressive when you consider that an expert virtual system pattern (VSP) developer can create a pattern of this complexity within a few weeks.
Beyond this very tangible savings is the fact that these consistent rapid stable deployments enable new ways of working. When teams start considering these very complex test systems as disposable then doors open to very innovative approaches to system test. You can see why VSPs are a strategic element in our approach to continuous delivery. More on that in a future post.
Kevin WilliamsSystem Test Architect
IBM Rational
 (No Ratings Yet)
(No Ratings Yet)Authors
 Adam Archer (1)
Adam Archer (1) Adam Neal (1)
Adam Neal (1) Adrian Cho (15)
Adrian Cho (15) Alice Connors (3)
Alice Connors (3) Amy Silberbauer (24)
Amy Silberbauer (24) Andrew Hans (1)
Andrew Hans (1) Andy Lapping (15)
Andy Lapping (15) Anindita Basu (3)
Anindita Basu (3) Anthony Hunter (1)
Anthony Hunter (1) Benjamin Pasero (5)
Benjamin Pasero (5) Benjamin Williams (3)
Benjamin Williams (3) Bernie Coyne (6)
Bernie Coyne (6) Beth Zukowsky (2)
Beth Zukowsky (2) Bhawana Gupta (11)
Bhawana Gupta (11) Bianca Jiang (3)
Bianca Jiang (3) Bill Higgins (2)
Bill Higgins (2) Boris Kuschel (2)
Boris Kuschel (2) Brent Barkman (2)
Brent Barkman (2) Brian Bryson (1)
Brian Bryson (1) Brian King (4)
Brian King (4) Brian Lang (2)
Brian Lang (2) Brian Massey (3)
Brian Massey (3) Brian Sanders (2)
Brian Sanders (2) Bruce MacIsaac (2)
Bruce MacIsaac (2) Carlos Ferreira (1)
Carlos Ferreira (1) Carolyn Pampino (10)
Carolyn Pampino (10) Catherine Burrows (1)
Catherine Burrows (1) Chandra Venkatapathy (1)
Chandra Venkatapathy (1) Chris Daly (1)
Chris Daly (1) Chris Trobridge (1)
Chris Trobridge (1) Christophe Cornu (3)
Christophe Cornu (3) Christophe Elek (5)
Christophe Elek (5) Christophe Telep (14)
Christophe Telep (14) Clara Forero (1)
Clara Forero (1) Clare Carty (4)
Clare Carty (4) Dan Barbour (1)
Dan Barbour (1) Dan Griffin (5)
Dan Griffin (5) Dan Leroux (2)
Dan Leroux (2) Daniel Berg (2)
Daniel Berg (2) Daniel Moul (27)
Daniel Moul (27) Daniel Toczala (4)
Daniel Toczala (4) Darin Swanson (1)
Darin Swanson (1) Darrel Rader (1)
Darrel Rader (1) Dave Thomson (7)
Dave Thomson (7) David Brauneis (1)
David Brauneis (1) David Hodges (1)
David Hodges (1) Dejan Glozic (2)
Dejan Glozic (2) Denise Cook (1)
Denise Cook (1) Derek Baron (8)
Derek Baron (8) Dibbe Edwards (3)
Dibbe Edwards (3) Dirk Baeumer (1)
Dirk Baeumer (1) Don Yantzi (1)
Don Yantzi (1) Doron Ben-Ari (3)
Doron Ben-Ari (3) ELM Engineering (42)
ELM Engineering (42) Eran Gery (1)
Eran Gery (1) Erich Gamma (5)
Erich Gamma (5) Erik Craig (1)
Erik Craig (1) Ernest Mah (1)
Ernest Mah (1) Evan Hughes (3)
Evan Hughes (3) Fariz Saracevic (16)
Fariz Saracevic (16) Frederic Fusier (1)
Frederic Fusier (1) Gary Cernosek (1)
Gary Cernosek (1) George DeCandio (4)
George DeCandio (4) Gili Mendel (1)
Gili Mendel (1) Ginny Ghezzo (1)
Ginny Ghezzo (1) Graham Bleakley (5)
Graham Bleakley (5) Grant Covell (1)
Grant Covell (1) Greg Gorman (1)
Greg Gorman (1) Guy Slade (1)
Guy Slade (1) Hadar Hawk (2)
Hadar Hawk (2) Heidi Stadel (1)
Heidi Stadel (1) James Branigan (2)
James Branigan (2) James Moody (2)
James Moody (2) Jan Wloka (2)
Jan Wloka (2) Jared Pulham (7)
Jared Pulham (7) Jean-Michel Lemieux (23)
Jean-Michel Lemieux (23) Jeanette Deupree (1)
Jeanette Deupree (1) Jim Amsden (1)
Jim Amsden (1) Jim D'Anjou (2)
Jim D'Anjou (2) Jim Ruehlin (1)
Jim Ruehlin (1) Johannes Rieken (2)
Johannes Rieken (2) John Kellerman (2)
John Kellerman (2) John Vasta (1)
John Vasta (1) John Whitfield (2)
John Whitfield (2) John Wiegand (1)
John Wiegand (1) Jozef deVries (1)
Jozef deVries (1) Kai-Uwe Maetzel (6)
Kai-Uwe Maetzel (6) Kalena Kelly (1)
Kalena Kelly (1) Karen Gosciminski (1)
Karen Gosciminski (1) Kate Draper (2)
Kate Draper (2) Kate Hauser (1)
Kate Hauser (1)- Kevin Williams (2)
 Kim Peter (10)
Kim Peter (10) Kiran M N (1)
Kiran M N (1) Kit Lo (1)
Kit Lo (1) Kourken Aroyan (1)
Kourken Aroyan (1) Kumaraswamy Gowda (15)
Kumaraswamy Gowda (15) Lauren Hayward Schaefer (15)
Lauren Hayward Schaefer (15) Lawrence Mandel (2)
Lawrence Mandel (2) Linda Watson (3)
Linda Watson (3) Liz Bonesteel (1)
Liz Bonesteel (1) Luc Hatlestad (1)
Luc Hatlestad (1) Lucinio Santos (1)
Lucinio Santos (1) Maneesh Mehra (3)
Maneesh Mehra (3) Manoj Panda (1)
Manoj Panda (1) Mario Maldari (1)
Mario Maldari (1) Mark Guertin (2)
Mark Guertin (2) Martha Andrews (3)
Martha Andrews (3) Mary Yost (1)
Mary Yost (1) Masabumi Koinuma (1)
Masabumi Koinuma (1) Mats Gothe (1)
Mats Gothe (1) Matt Lavin (1)
Matt Lavin (1) Michael Fiedler (1)
Michael Fiedler (1) Michael Halder (2)
Michael Halder (2) Michael Valenta (3)
Michael Valenta (3) Millard Ellingsworth (3)
Millard Ellingsworth (3) Miran Badzak (1)
Miran Badzak (1) Monica Luke (5)
Monica Luke (5) Moshe Cohen (1)
Moshe Cohen (1) Nadra Rafee (1)
Nadra Rafee (1) Nathan Bak (5)
Nathan Bak (5) Neil Leblanc (3)
Neil Leblanc (3) Nick Crossley (3)
Nick Crossley (3) Nithya Rajagopalan (3)
Nithya Rajagopalan (3) Palak Sheth (1)
Palak Sheth (1) Patrick Streule (1)
Patrick Streule (1) Paul Ellis (1)
Paul Ellis (1) Paul Strachan (1)
Paul Strachan (1) Paul Tasillo (2)
Paul Tasillo (2) Peter Haumer (1)
Peter Haumer (1) Peter Steinfeld (1)
Peter Steinfeld (1) Phil Vogel (3)
Phil Vogel (3) Priyadarshini Gorur (3)
Priyadarshini Gorur (3) Rahul Choudhary (4)
Rahul Choudhary (4) Reuben Varzea (12)
Reuben Varzea (12) Richard Bone (3)
Richard Bone (3) Richard Watson (13)
Richard Watson (13) Rishikesh Agam (2)
Rishikesh Agam (2) Robbie Minshall (1)
Robbie Minshall (1) Robin Bater (5)
Robin Bater (5) Roger LeBlanc (1)
Roger LeBlanc (1) Rolf Nelson (16)
Rolf Nelson (16) Rosa Naranjo (1)
Rosa Naranjo (1) Rosalind Radcliffe (1)
Rosalind Radcliffe (1) Ryan Manwiller (4)
Ryan Manwiller (4) Sandeep Kohli (1)
Sandeep Kohli (1) Sandeep Somavarapu (1)
Sandeep Somavarapu (1) Sanjesh Nair (1)
Sanjesh Nair (1) Scott Rich (13)
Scott Rich (13) Sean Babineau (1)
Sean Babineau (1) Seth Packham (11)
Seth Packham (11) Sharoon Shetty Kuriyala (1)
Sharoon Shetty Kuriyala (1) Sreerupa Sen (5)
Sreerupa Sen (5) Sridevi Sangaiah (1)
Sridevi Sangaiah (1) Steve DiCamillo (2)
Steve DiCamillo (2) Steven Beard (1)
Steven Beard (1) Subramanya Pilar (6)
Subramanya Pilar (6) Sujan Surendrananitha (2)
Sujan Surendrananitha (2) Suneel Santharam (2)
Suneel Santharam (2) Susan Yeshin (1)
Susan Yeshin (1) Tim Feeney (7)
Tim Feeney (7) Tod Creasey (1)
Tod Creasey (1) Tom Hollowell (4)
Tom Hollowell (4) Ubaidu Peediakkal (3)
Ubaidu Peediakkal (3) Vaibhav Srivastava (1)
Vaibhav Srivastava (1) Vandana Shenoy (1)
Vandana Shenoy (1) Vatsalkumar Parmar (2)
Vatsalkumar Parmar (2) Virginia Lovering (1)
Virginia Lovering (1) Will Streit (1)
Will Streit (1)
You must be logged in to post a comment.