
About a month ago, my wife, who has lived through 20 years of software deliveries with me at IBM, turned to me and asked “Aren’t you guys shipping Rational Team Concert real soon now? You don’t seem nearly stressed out enough – is it still happening?” I assured her that we were still shipping on time, but that, for some reason, this was the smoothest delivery I had ever experienced.
Talking to other PMC and development team members, I observed how well the end-game was going, and got universal agreement. No one had been involved in anything that shipped this easily, which is even more amazing given the complexity and importance of the Rational Team Concert 1.0 release. So I followed up asking “Why is it so easy this time?”
In hallway conversations, on PMC calls, over beers at the Rational Software Development Conference, and in team retrospectives, here are some of the explanations we heard.
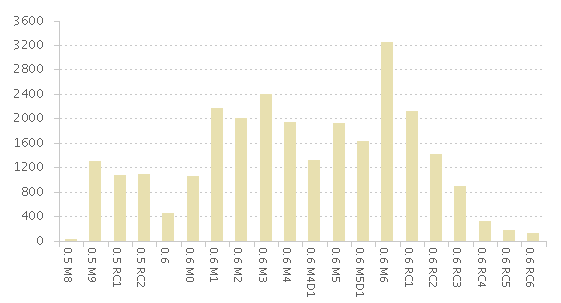
“The plan just worked, we shut down major feature development early, and (excepting licensing and install) most teams were in bug-fix mode by M6.” OK, that works. There’s a report available now which shows bugs Closed by Iteration, and it shows fixing ramping down exactly as we hoped. M6 was the last big spike, and each subsequent iteration came close to our goal of reducing fixing by half.
“Self-hosting did it. Rational Team Concert is ready to ship because our self-hosting has forced it to be good.” Definitely agree with this one. In fact, from now on, I only want to work on software that has the unfair advantage of self-hosting.
“The process rules enacted for the end-game, requiring reviews and approvals, made it happen.” As we entered the end-game, we turned on process rules that required approvals for fixes to be delivered. Any code delivery had to be associated with a work item which had an attached approval. Each iteration in the end-game, we increased the required approvals and reviews. In RC5 and RC6, we required two code reviews, a team lead approval, and two PMC approvals. The two PMC approvals seemed to work especially well, as it enabled a “good cop/bad cop” approach where needed, with a single PMC “no” vetoing a fix. After a few of these, the team understood we were serious about evaluating the risk/reward of any code changes.
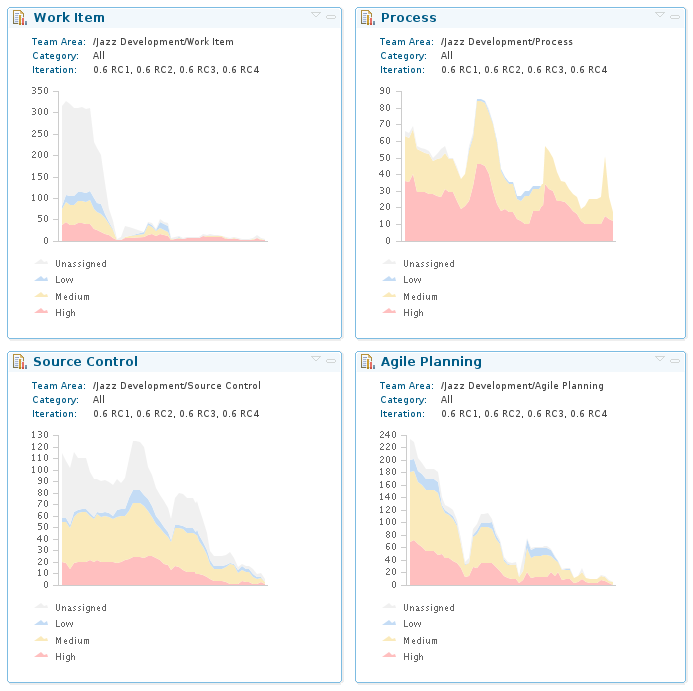
“The whole project had visibility to what was going on, and was able to adjust course to make sure we succeeded.” In the end-game, the PMC actively developed the Jazz Development dashboard to promote this shared awareness. Tabs devoted to candidate bugs gave a view at a glance at what was being targeted and checked off progress. Burndown charts showed that the brakes were working and the code was settling down. Erich says “Making things visible is the first step to make things happen.”

And, finally: “We’re just way better and smarter than we’ve ever been…” OK, Kevin and I made that one up…
—
Scott Rich
Jazz Foundation Lead

 (7 votes, average: 4.14 out of 5)
(7 votes, average: 4.14 out of 5)You must be logged in to post a comment.
Authors
 Adam Archer (1)
Adam Archer (1) Adam Neal (1)
Adam Neal (1) Adrian Cho (15)
Adrian Cho (15) Alice Connors (3)
Alice Connors (3) Amy Silberbauer (24)
Amy Silberbauer (24) Andrew Hans (1)
Andrew Hans (1) Andy Lapping (15)
Andy Lapping (15) Anindita Basu (3)
Anindita Basu (3) Anthony Hunter (1)
Anthony Hunter (1) Benjamin Pasero (5)
Benjamin Pasero (5) Benjamin Williams (3)
Benjamin Williams (3) Bernie Coyne (6)
Bernie Coyne (6) Beth Zukowsky (2)
Beth Zukowsky (2) Bhawana Gupta (11)
Bhawana Gupta (11) Bianca Jiang (3)
Bianca Jiang (3) Bill Higgins (2)
Bill Higgins (2) Boris Kuschel (2)
Boris Kuschel (2) Brent Barkman (2)
Brent Barkman (2) Brian Bryson (1)
Brian Bryson (1) Brian King (4)
Brian King (4) Brian Lang (2)
Brian Lang (2) Brian Massey (3)
Brian Massey (3) Brian Sanders (2)
Brian Sanders (2) Bruce MacIsaac (2)
Bruce MacIsaac (2) Carlos Ferreira (1)
Carlos Ferreira (1) Carolyn Pampino (10)
Carolyn Pampino (10) Catherine Burrows (1)
Catherine Burrows (1) Chandra Venkatapathy (1)
Chandra Venkatapathy (1) Chris Daly (1)
Chris Daly (1) Chris Trobridge (1)
Chris Trobridge (1) Christophe Cornu (3)
Christophe Cornu (3) Christophe Elek (5)
Christophe Elek (5) Christophe Telep (14)
Christophe Telep (14) Clara Forero (1)
Clara Forero (1) Clare Carty (4)
Clare Carty (4) Dan Barbour (1)
Dan Barbour (1) Dan Griffin (5)
Dan Griffin (5) Dan Leroux (2)
Dan Leroux (2) Daniel Berg (2)
Daniel Berg (2) Daniel Moul (27)
Daniel Moul (27) Daniel Toczala (4)
Daniel Toczala (4) Darin Swanson (1)
Darin Swanson (1) Darrel Rader (1)
Darrel Rader (1) Dave Thomson (7)
Dave Thomson (7) David Brauneis (1)
David Brauneis (1) David Hodges (1)
David Hodges (1) Dejan Glozic (2)
Dejan Glozic (2) Denise Cook (1)
Denise Cook (1) Derek Baron (8)
Derek Baron (8) Dibbe Edwards (3)
Dibbe Edwards (3) Dirk Baeumer (1)
Dirk Baeumer (1) Don Yantzi (1)
Don Yantzi (1) Doron Ben-Ari (3)
Doron Ben-Ari (3) ELM Engineering (42)
ELM Engineering (42) Eran Gery (1)
Eran Gery (1) Erich Gamma (5)
Erich Gamma (5) Erik Craig (1)
Erik Craig (1) Ernest Mah (1)
Ernest Mah (1) Evan Hughes (3)
Evan Hughes (3) Fariz Saracevic (16)
Fariz Saracevic (16) Frederic Fusier (1)
Frederic Fusier (1) Gary Cernosek (1)
Gary Cernosek (1) George DeCandio (4)
George DeCandio (4) Gili Mendel (1)
Gili Mendel (1) Ginny Ghezzo (1)
Ginny Ghezzo (1) Graham Bleakley (5)
Graham Bleakley (5) Grant Covell (1)
Grant Covell (1) Greg Gorman (1)
Greg Gorman (1) Guy Slade (1)
Guy Slade (1) Hadar Hawk (2)
Hadar Hawk (2) Heidi Stadel (1)
Heidi Stadel (1) James Branigan (2)
James Branigan (2) James Moody (2)
James Moody (2) Jan Wloka (2)
Jan Wloka (2) Jared Pulham (7)
Jared Pulham (7) Jean-Michel Lemieux (23)
Jean-Michel Lemieux (23) Jeanette Deupree (1)
Jeanette Deupree (1) Jim Amsden (1)
Jim Amsden (1) Jim D'Anjou (2)
Jim D'Anjou (2) Jim Ruehlin (1)
Jim Ruehlin (1) Johannes Rieken (2)
Johannes Rieken (2) John Kellerman (2)
John Kellerman (2) John Vasta (1)
John Vasta (1) John Whitfield (2)
John Whitfield (2) John Wiegand (1)
John Wiegand (1) Jozef deVries (1)
Jozef deVries (1) Kai-Uwe Maetzel (6)
Kai-Uwe Maetzel (6) Kalena Kelly (1)
Kalena Kelly (1) Karen Gosciminski (1)
Karen Gosciminski (1) Kate Draper (2)
Kate Draper (2) Kate Hauser (1)
Kate Hauser (1) Kevin Williams (2)
Kevin Williams (2) Kim Peter (10)
Kim Peter (10) Kiran M N (1)
Kiran M N (1) Kit Lo (1)
Kit Lo (1) Kourken Aroyan (1)
Kourken Aroyan (1) Kumaraswamy Gowda (15)
Kumaraswamy Gowda (15) Lauren Hayward Schaefer (15)
Lauren Hayward Schaefer (15) Lawrence Mandel (2)
Lawrence Mandel (2) Linda Watson (3)
Linda Watson (3) Liz Bonesteel (1)
Liz Bonesteel (1) Luc Hatlestad (1)
Luc Hatlestad (1) Lucinio Santos (1)
Lucinio Santos (1) Maneesh Mehra (3)
Maneesh Mehra (3) Manoj Panda (1)
Manoj Panda (1) Mario Maldari (1)
Mario Maldari (1) Mark Guertin (2)
Mark Guertin (2) Martha Andrews (3)
Martha Andrews (3) Mary Yost (1)
Mary Yost (1) Masabumi Koinuma (1)
Masabumi Koinuma (1) Mats Gothe (1)
Mats Gothe (1) Matt Lavin (1)
Matt Lavin (1) Michael Fiedler (1)
Michael Fiedler (1) Michael Halder (2)
Michael Halder (2) Michael Valenta (3)
Michael Valenta (3) Millard Ellingsworth (3)
Millard Ellingsworth (3) Miran Badzak (1)
Miran Badzak (1) Monica Luke (5)
Monica Luke (5) Moshe Cohen (1)
Moshe Cohen (1) Nadra Rafee (1)
Nadra Rafee (1) Nathan Bak (5)
Nathan Bak (5) Neil Leblanc (3)
Neil Leblanc (3) Nick Crossley (3)
Nick Crossley (3) Nithya Rajagopalan (3)
Nithya Rajagopalan (3) Palak Sheth (1)
Palak Sheth (1) Patrick Streule (1)
Patrick Streule (1) Paul Ellis (1)
Paul Ellis (1) Paul Strachan (1)
Paul Strachan (1) Paul Tasillo (2)
Paul Tasillo (2) Peter Haumer (1)
Peter Haumer (1) Peter Steinfeld (1)
Peter Steinfeld (1) Phil Vogel (3)
Phil Vogel (3) Priyadarshini Gorur (3)
Priyadarshini Gorur (3) Rahul Choudhary (4)
Rahul Choudhary (4) Reuben Varzea (12)
Reuben Varzea (12) Richard Bone (3)
Richard Bone (3) Richard Watson (13)
Richard Watson (13) Rishikesh Agam (2)
Rishikesh Agam (2) Robbie Minshall (1)
Robbie Minshall (1) Robin Bater (5)
Robin Bater (5) Roger LeBlanc (1)
Roger LeBlanc (1) Rolf Nelson (16)
Rolf Nelson (16) Rosa Naranjo (1)
Rosa Naranjo (1) Rosalind Radcliffe (1)
Rosalind Radcliffe (1) Ryan Manwiller (4)
Ryan Manwiller (4) Sandeep Kohli (1)
Sandeep Kohli (1) Sandeep Somavarapu (1)
Sandeep Somavarapu (1) Sanjesh Nair (1)
Sanjesh Nair (1)- Scott Rich (13)
 Sean Babineau (1)
Sean Babineau (1) Seth Packham (11)
Seth Packham (11) Sharoon Shetty Kuriyala (1)
Sharoon Shetty Kuriyala (1) Sreerupa Sen (5)
Sreerupa Sen (5) Sridevi Sangaiah (1)
Sridevi Sangaiah (1) Steve DiCamillo (2)
Steve DiCamillo (2) Steven Beard (1)
Steven Beard (1) Subramanya Pilar (6)
Subramanya Pilar (6) Sujan Surendrananitha (2)
Sujan Surendrananitha (2) Suneel Santharam (2)
Suneel Santharam (2) Susan Yeshin (1)
Susan Yeshin (1) Tim Feeney (7)
Tim Feeney (7) Tod Creasey (1)
Tod Creasey (1) Tom Hollowell (4)
Tom Hollowell (4) Ubaidu Peediakkal (3)
Ubaidu Peediakkal (3) Vaibhav Srivastava (1)
Vaibhav Srivastava (1) Vandana Shenoy (1)
Vandana Shenoy (1) Vatsalkumar Parmar (2)
Vatsalkumar Parmar (2) Virginia Lovering (1)
Virginia Lovering (1) Will Streit (1)
Will Streit (1)
Good observations by all, and I agree wholeheartedly (especially with the last one ). The advantage of self-hosting is very very powerful, and the visibility and subsequent awareness (by all team members) gave everyone more of a “personal stake” in the endgame.
BTW, if you mentally “stack” M4D1 + M4, and M5D1 + M5, in the first chart, you’ll see even better a high-point around M5 (with each of M4, M5 and M6 being extremely busy) which makes the resulting picture even smoother. I was pleasantly surprised when I first saw this chart.
james
Excellent post. I think the visibility was key, especially given the fact that the team was so distributed. Any team can benefit from the developer and business visibility that RTC provides, but for distributed teams I believe it is a must have.
Great post Scott, along with the fact that we were releasing Release Candidates every friday provided more credibility to our statement that we have workable code at every milestone. Add to the fact the we had nothing to hide from a delivery perspective and that most of the team members are all distributed. To orchestrate such a smooth end game, is something to celebrate about.
This was a really interesting post, thanks for sharing. It’s funny, with all the effort we put into metrics (i.e. burndown charts, velocity, etc, etc), sometimes the most important metric is just what your wife thinks :)
hey dad great article! i liked it but mention me next time!
Scott:
This was great – so many times you hear about what went wrong in a project. It’s great to hear about what went right.
Mike
Hey Scott, I’ve recently had some new perspective on this. I am in the middle of a tough endgame with one of our new cloud products and was talking to Jamie Thomas about the difference between the Team Concert 1.0 endgame and this current cloud endgame.
In hindsight, one of the biggest benefits Team Concert 1.0 had was that the architecture had basically stabilized several years before we had to ship. I remember one of the toughest pushes for Team Concert was getting to the “unzip install” for OOPSLA 2006. If you recall it was really tough to get all of the components into a simple package, but that same basic unzip install persists to this day. After that there were some incremental architectural changes (e.g. progressively changing operations to be process-enabled, optional Installation Manager-based installer) but the architecture was pretty stable.
Another thing Team Concert 1.0 had going for it was that the architecture was extremely homogenous. Everything was a plug-in and everything was based on the same core APIs and extension points. In the case of both early WebSphere Application Server and our new cloud product, they are the combination of several components that were designed in isolation from one another and then later integrated to form the product.
So while your blog entry above rightfully points out some process aspects that led to a smooth endgame, in hindsight I think it also was largely due to the architectural stability and self-consistency.
@ Bill – This seems to be a lesson that we refuse to learn:
“the cost of reusing whole products is often much higher than to rewrite”
An ironic example was that a year ago we already had the core pattern engine from vApps built natively on top of HSLT. I year later the integration between the two products is not nearly as clean, effective, simple, and robust.
Prior to acquisition, most of our end games were much like Rich’s story. Although, we weren’t self hosted. We had a small team of “A players” all in one location – literally in one big room. As problems came up – they were visible to all and quick discussion followed by quick decisive action ensued.
The counter point to your comment about architecture is that many cloud based apps like instagram have great stories about swapping in/out major parts of their architecture very quickly.
There is no substitute for competence and no substitute for being in the same place. As for architecture changes, I think there is also no substitute for decent code. Nasty code that no single individual actually knows will always be fragile and difficult to change/evolve. You can only evolve code you know and that is well written. From my experience, picking up lots of open source code can be very effective because you can see the code. If it’s nasty you steer clear. If it’s good, clear, and workable – then you can do it very efficiently.
In summary, there is no substitute for competence, collocation, and code – the 3Cs :-)
Thanks for the interesting conversation, Bill and Andrew, although I have to add that we were not advantaged with Collocation. The RTC 1.0 team was simpler than CLM is today, but it was already spread across at least 5 sites spanning nine timezones. Component teams were largely collocated, but we had to learn to collaborate and integrate across sites to build the product.