
Before generating a document with IBM Engineering Lifecycle Optimization – Publishing (PUB), end-users must configure the data source and provide a number of inputs. Though this cannot be avoided, we can make the user experience better by enabling value selection instead of manually entering the values, thanks to the Configuration Layer in PUB.
Configuration layer in PUB template allows the end-user to select URLs from a drop-down instead of typing them. End-user will be shown a list of readable values (ID, title, etc.) as the labels for the URLs. The configuration layer also helps in setting values for template variables wherever applicable. ETM, EWM, RMM use configuration layer to support document generation from Web UI. In this blog, we will see how it can be done for document generation from Publishing Launcher.
Edit Configuration Metadata in Publishing Studio
To add or edit configuration metadata for a data source or variable, you need to edit the template in Publishing Studio. In Outline view, right-click on the data source that needs to be configured and select “Edit Configuration Metadata”. Usually, this data source is the parent data source that the end-user has to configure – one that is not dynamically configured and the name does not start with “_”.
There are 4 fields in the “Edit Configuration Metadata…” window.
Type – restricts the format of user input.
Identifier – XPath expression that selects the data PUB will use to configure the report. The values of this attribute must be Reportable REST URLs.
Display – XPath expression that selects the data PUB will show the user.
Request URL – the URL on which PUB will make data request. There are pre-defined variables that can be used in this field that point products will recognize. You cannot use these values if configuring the report from standalone Publishing.
$public: Public URL of the server
$projectAreaUUID: project area.
Note: You can drag and drop attributes from Data Source View into the identifier and display fields.
How PUB uses these values?
If the Request URL is not set, then user has to manually input the data source value when executing the report. If the Request URL is set, and the Identifier field is not set, the resolved value of the Request URL will be used for report generation.
If both Request URL and Identifier fields are set, a GET request to the resolved Request URL is made, then Identifier and Display XPath expressions are evaluated on the server response and a list is shown to user to choose from. The values matching Display expression are shown in the list and the corresponding value of Identifier is set as data source URI.
Note: The identifier XPath and display XPath must return collections of equal size and in the same order since PUB will match them 1:1 in the order they are received.
Example 1 (setting URI for data sources):
A template that reports on ETM test case details needs to be configured with an URL that looks likes this:
https://sppelm:9443/qm/service/com.ibm.rqm.integration.service.IIntegrationService/resources/JKE+Banking+%28Quality+Management%29/testcase/urn:com.ibm.rqm:testcase:20
There are chances of human error while end-user enters this URL. In contrast, the configuration layer provides a drop-down so that end-user can select any test case. The URL for the selected test case will be used to configure test case data source and there is no room for error.
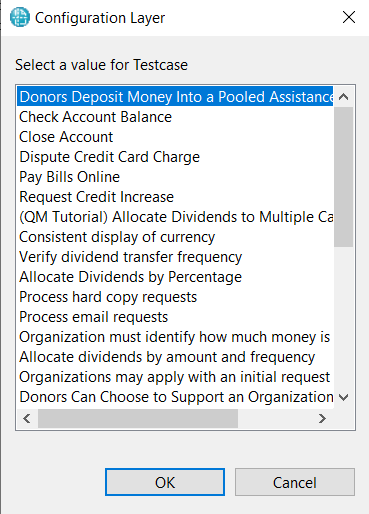
The dialog presents the user with the list of the test case titles from the JKE Banking project area in ETM. When the end-user selects an entry from the drop-down, PUB configures the data source to the Reportable REST URL of that test case.
This feature is accessed from the context menu of the data source in PUB Launcher and is visible only if the data source has configuration metadata associated with it in the template.

What happens in the background?

1. PUB makes a GET request to the address specified in the Request URL. End-user is prompted to authenticate if needed.
2. PUB reads the XML returned and executes the identifier XPath on it. Assuming the XPath is valid this will return a list of strings.
3. Since the display XPath is set, PUB executes it on the same XML to build the string labels.
4. PUB shows the list returned by the display XPath to the end-user. Each label is associated with a corresponding identifier.
5. On selecting a particular test case title, its identifier is used as the data source URI.
Example 2 (providing values for template variables):
Suppose we have to list all the category values for EWM WorkItems, this is how the category variable has to be configured:
Type: string
Identifier: /workitem/category/name
Display: /workitem/category/name
Request URL: ${public}/rpt/repository/workitem?fields=workitem/category/name

List of category names is shown to user when he selects “Configure using Metadata”.

You may note the difference between fields=workitem/category and fields=workitem/workItem/category. The latter will return only those categories that have one or more WorkItems assigned to them.

You can consider using configuration layer to shift the complexity from the end-user to the template designer. The Template designer adds his knowledge in the template so that user can set the URI for data sources and provide values for template variables without any error. This makes document generation easy even for non-technical users.
Subramanya Prasad Pilar
IBM Engineering Lifecycle Optimization – Publishing
 (2 votes, average: 5.00 out of 5)
(2 votes, average: 5.00 out of 5)Authors
 Adam Archer (1)
Adam Archer (1) Adam Neal (1)
Adam Neal (1) Adrian Cho (15)
Adrian Cho (15) Alice Connors (3)
Alice Connors (3) Amy Silberbauer (24)
Amy Silberbauer (24) Andrew Hans (1)
Andrew Hans (1) Andy Lapping (15)
Andy Lapping (15) Anindita Basu (3)
Anindita Basu (3) Anthony Hunter (1)
Anthony Hunter (1) Benjamin Pasero (5)
Benjamin Pasero (5) Benjamin Williams (3)
Benjamin Williams (3) Bernie Coyne (6)
Bernie Coyne (6) Beth Zukowsky (2)
Beth Zukowsky (2) Bhawana Gupta (10)
Bhawana Gupta (10) Bianca Jiang (3)
Bianca Jiang (3) Bill Higgins (2)
Bill Higgins (2) Boris Kuschel (2)
Boris Kuschel (2) Brent Barkman (2)
Brent Barkman (2) Brian Bryson (1)
Brian Bryson (1) Brian King (4)
Brian King (4) Brian Lang (2)
Brian Lang (2) Brian Massey (3)
Brian Massey (3) Brian Sanders (2)
Brian Sanders (2) Bruce MacIsaac (2)
Bruce MacIsaac (2) Carlos Ferreira (1)
Carlos Ferreira (1) Carolyn Pampino (10)
Carolyn Pampino (10) Catherine Burrows (1)
Catherine Burrows (1) Chandra Venkatapathy (1)
Chandra Venkatapathy (1) Chris Daly (1)
Chris Daly (1) Chris Trobridge (1)
Chris Trobridge (1) Christophe Cornu (3)
Christophe Cornu (3) Christophe Elek (5)
Christophe Elek (5) Christophe Telep (14)
Christophe Telep (14) Clara Forero (1)
Clara Forero (1) Clare Carty (4)
Clare Carty (4) Dan Barbour (1)
Dan Barbour (1) Dan Griffin (5)
Dan Griffin (5) Dan Leroux (2)
Dan Leroux (2) Daniel Berg (2)
Daniel Berg (2) Daniel Moul (27)
Daniel Moul (27) Daniel Toczala (4)
Daniel Toczala (4) Darin Swanson (1)
Darin Swanson (1) Darrel Rader (1)
Darrel Rader (1) Dave Thomson (7)
Dave Thomson (7) David Brauneis (1)
David Brauneis (1) David Hodges (1)
David Hodges (1) Dejan Glozic (2)
Dejan Glozic (2) Denise Cook (1)
Denise Cook (1) Derek Baron (8)
Derek Baron (8) Dibbe Edwards (3)
Dibbe Edwards (3) Dirk Baeumer (1)
Dirk Baeumer (1) Don Yantzi (1)
Don Yantzi (1) Doron Ben-Ari (3)
Doron Ben-Ari (3) ELM Engineering (42)
ELM Engineering (42) Eran Gery (1)
Eran Gery (1) Erich Gamma (5)
Erich Gamma (5) Erik Craig (1)
Erik Craig (1) Ernest Mah (1)
Ernest Mah (1) Evan Hughes (3)
Evan Hughes (3) Fariz Saracevic (16)
Fariz Saracevic (16) Frederic Fusier (1)
Frederic Fusier (1) Gary Cernosek (1)
Gary Cernosek (1) George DeCandio (4)
George DeCandio (4) Gili Mendel (1)
Gili Mendel (1) Ginny Ghezzo (1)
Ginny Ghezzo (1) Graham Bleakley (5)
Graham Bleakley (5) Grant Covell (1)
Grant Covell (1) Greg Gorman (1)
Greg Gorman (1) Guy Slade (1)
Guy Slade (1) Hadar Hawk (2)
Hadar Hawk (2) Heidi Stadel (1)
Heidi Stadel (1) James Branigan (2)
James Branigan (2) James Moody (2)
James Moody (2) Jan Wloka (2)
Jan Wloka (2) Jared Pulham (7)
Jared Pulham (7) Jean-Michel Lemieux (23)
Jean-Michel Lemieux (23) Jeanette Deupree (1)
Jeanette Deupree (1) Jim Amsden (1)
Jim Amsden (1) Jim D'Anjou (2)
Jim D'Anjou (2) Jim Ruehlin (1)
Jim Ruehlin (1) Johannes Rieken (2)
Johannes Rieken (2) John Kellerman (2)
John Kellerman (2) John Vasta (1)
John Vasta (1) John Whitfield (2)
John Whitfield (2) John Wiegand (1)
John Wiegand (1) Jozef deVries (1)
Jozef deVries (1) Kai-Uwe Maetzel (6)
Kai-Uwe Maetzel (6) Kalena Kelly (1)
Kalena Kelly (1) Karen Gosciminski (1)
Karen Gosciminski (1) Kate Draper (2)
Kate Draper (2) Kate Hauser (1)
Kate Hauser (1) Kevin Williams (2)
Kevin Williams (2) Kim Peter (10)
Kim Peter (10) Kiran M N (1)
Kiran M N (1) Kit Lo (1)
Kit Lo (1) Kourken Aroyan (1)
Kourken Aroyan (1) Kumaraswamy Gowda (15)
Kumaraswamy Gowda (15) Lauren Hayward Schaefer (15)
Lauren Hayward Schaefer (15) Lawrence Mandel (2)
Lawrence Mandel (2) Linda Watson (3)
Linda Watson (3) Liz Bonesteel (1)
Liz Bonesteel (1) Luc Hatlestad (1)
Luc Hatlestad (1) Lucinio Santos (1)
Lucinio Santos (1) Maneesh Mehra (3)
Maneesh Mehra (3) Manoj Panda (1)
Manoj Panda (1) Mario Maldari (1)
Mario Maldari (1) Mark Guertin (2)
Mark Guertin (2) Martha Andrews (3)
Martha Andrews (3) Mary Yost (1)
Mary Yost (1) Masabumi Koinuma (1)
Masabumi Koinuma (1) Mats Gothe (1)
Mats Gothe (1) Matt Lavin (1)
Matt Lavin (1) Michael Fiedler (1)
Michael Fiedler (1) Michael Halder (2)
Michael Halder (2) Michael Valenta (3)
Michael Valenta (3) Millard Ellingsworth (3)
Millard Ellingsworth (3) Miran Badzak (1)
Miran Badzak (1) Monica Luke (5)
Monica Luke (5) Moshe Cohen (1)
Moshe Cohen (1) Nadra Rafee (1)
Nadra Rafee (1) Nathan Bak (5)
Nathan Bak (5) Neil Leblanc (3)
Neil Leblanc (3) Nick Crossley (3)
Nick Crossley (3) Nithya Rajagopalan (3)
Nithya Rajagopalan (3) Palak Sheth (1)
Palak Sheth (1) Patrick Streule (1)
Patrick Streule (1) Paul Ellis (1)
Paul Ellis (1) Paul Strachan (1)
Paul Strachan (1) Paul Tasillo (2)
Paul Tasillo (2) Peter Haumer (1)
Peter Haumer (1) Peter Steinfeld (1)
Peter Steinfeld (1) Phil Vogel (3)
Phil Vogel (3) Priyadarshini Gorur (3)
Priyadarshini Gorur (3) Rahul Choudhary (4)
Rahul Choudhary (4) Reuben Varzea (12)
Reuben Varzea (12) Richard Bone (3)
Richard Bone (3) Richard Watson (13)
Richard Watson (13) Rishikesh Agam (2)
Rishikesh Agam (2) Robbie Minshall (1)
Robbie Minshall (1) Robin Bater (5)
Robin Bater (5) Roger LeBlanc (1)
Roger LeBlanc (1) Rolf Nelson (16)
Rolf Nelson (16) Rosa Naranjo (1)
Rosa Naranjo (1) Rosalind Radcliffe (1)
Rosalind Radcliffe (1) Ryan Manwiller (4)
Ryan Manwiller (4) Sandeep Kohli (1)
Sandeep Kohli (1) Sandeep Somavarapu (1)
Sandeep Somavarapu (1) Sanjesh Nair (1)
Sanjesh Nair (1) Scott Rich (13)
Scott Rich (13) Sean Babineau (1)
Sean Babineau (1) Seth Packham (11)
Seth Packham (11) Sharoon Shetty Kuriyala (1)
Sharoon Shetty Kuriyala (1) Sreerupa Sen (5)
Sreerupa Sen (5) Sridevi Sangaiah (1)
Sridevi Sangaiah (1) Steve DiCamillo (2)
Steve DiCamillo (2) Steven Beard (1)
Steven Beard (1)- Subramanya Pilar (6)
 Sujan Surendrananitha (2)
Sujan Surendrananitha (2) Suneel Santharam (2)
Suneel Santharam (2) Susan Yeshin (1)
Susan Yeshin (1) Tim Feeney (7)
Tim Feeney (7) Tod Creasey (1)
Tod Creasey (1) Tom Hollowell (4)
Tom Hollowell (4) Ubaidu Peediakkal (3)
Ubaidu Peediakkal (3) Vaibhav Srivastava (1)
Vaibhav Srivastava (1) Vandana Shenoy (1)
Vandana Shenoy (1) Vatsalkumar Parmar (2)
Vatsalkumar Parmar (2) Virginia Lovering (1)
Virginia Lovering (1) Will Streit (1)
Will Streit (1)
You must be logged in to post a comment.