![]() Long-running ETLs without error(s)
Long-running ETLs without error(s)
Authors: GeraldMitchell, StephanieBagot Build basis: CLM 4.x, 5.x
Page contents
- Why do my ETLs take so long to run?
- Initial assessment
- Possible causes and solutions
- The Data warehouse is configured to use the same database as the JTS/CCM/QM application
- There is too much data collected by the Job
- Too many jobs are running or the jobs are unnecessarily run
- Not enough system resources
- Database backups
- Outdated JDBC driver
- Custom SQL queries are causing delays in running ETLs
- Network delays
- Database tuning
- Other integrations
- Product specific enhancements
This situation is to help determine both cause and resolution where ETL (Extract, Transform, Load) processes take significantly longed than expected to run and there is no error present.
If an error has occurred, navigate to the Long Running ETL with Error page.
How do I know if I am running the Full Collection Job? Under the Data Collection Jobs page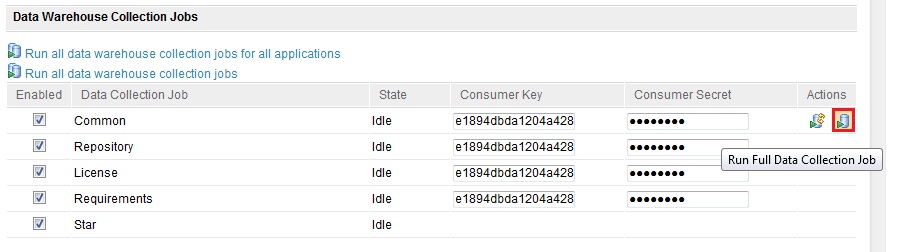 In addition delivery of data into the data warehouse is slow when projects contain too much data. It is possible to reduce the data delivered by customizing the ETL process to deliver raw data directly to a temporary table and then to separately transform that data into the target table. This requires the creation of a temporary table with the correct privileges, configuring the application server, customizing the ETL process, and executing the ETL job. See the Technote 1455870 for an example of Insight and Requisite Pro, though the general principal applies to all applications and data warehousing.
In addition delivery of data into the data warehouse is slow when projects contain too much data. It is possible to reduce the data delivered by customizing the ETL process to deliver raw data directly to a temporary table and then to separately transform that data into the target table. This requires the creation of a temporary table with the correct privileges, configuring the application server, customizing the ETL process, and executing the ETL job. See the Technote 1455870 for an example of Insight and Requisite Pro, though the general principal applies to all applications and data warehousing.
*Example:* The ANALYZE_TABLE command is already run by the ETL jobs, so it is redundant to have it run twice. The ANALYZE_TABLE command can be disabled through a new parameter in the Data Warehouse connection page named: Automatically update the database statistics. Source: Technote 1590790
Why do my ETLs take so long to run?
This situation is to help discover the possibilities in correcting ETLs in the situation where the ETLs seem to be taking what is considered a longer time than expected to run. This specific topic will cover instances when no error occurs.If an error has occurred, navigate to the Long Running ETL with Error page.
Initial assessment
After you have completed the Initial Troubleshooting, and the Initial Assessment ETL specific questions, you have been unable to identify any errors or other unexpected behaviour which is causing the long running ETL. This page will help to point you to where to investigate next.Possible causes and solutions
Significant improvements have been made to the performance of the ETL processes between 3.x and 4.x. Ensure you are running at least 4.0 to take advantage of these performance increases. Below are some possible causes and solutions we have experiences with long running ETL jobs:The Data warehouse is configured to use the same database as the JTS/CCM/QM application
The Data warehouse should be a seperate database than the JTS/CCM/QM application databases. Ensure that the JDBC Location connection string for the data warehouse, located onhttps://<servername>:9443/<app context root>/admin#action=com.ibm.team.reportsManagement.configureDataWarehouseConnectionpoints to a seperate database than the application database JDBC connectio string found on
https://<sever name>:9443/<app context>/admin#action=com.ibm.team.repository.admin.configureDatabaseConnection
There is too much data collected by the Job
Full data collection jobs occur during the initial run of the data collection jobs. These jobs take significantly longer than typical data collection jobs that run incremental, 'delta builds', which only collect changes from the last time that job was run. If you are manually initiating Data Collection, ensure that the Full Data Collection Job is not selected. Collecting too much data may also cause an error, as addressed in Long Running ETL with ErrorHow do I know if I am running the Full Collection Job? Under the Data Collection Jobs page
https://<servername>:9443/<app context>/admin#action=jazz.viewPage&id=com.ibm.team.reports.reportsManagementPageEach Data Collection job will be displayed. Under Actions, there are two buttons. The first is for the Delta Jobs and the second is for the Full Collection Job.
In addition delivery of data into the data warehouse is slow when projects contain too much data. It is possible to reduce the data delivered by customizing the ETL process to deliver raw data directly to a temporary table and then to separately transform that data into the target table. This requires the creation of a temporary table with the correct privileges, configuring the application server, customizing the ETL process, and executing the ETL job. See the Technote 1455870 for an example of Insight and Requisite Pro, though the general principal applies to all applications and data warehousing.
Too many jobs are running or the jobs are unnecessarily run
The ETL is data dependent and so should be treated as a queue, where only one ETL should be scheduled at a time. Additionally, ETL jobs that are duplicated or run too often can slow performance. Out of the box, the ETLs will run subsequently one after the other, so running multiple jobs should not be a concern. If you have customized any ETLs to run at the same time, this could cause the long running ETLs. Take a look into your customization to ensure no ETLs are running at the same time.*Example:* The ANALYZE_TABLE command is already run by the ETL jobs, so it is redundant to have it run twice. The ANALYZE_TABLE command can be disabled through a new parameter in the Data Warehouse connection page named: Automatically update the database statistics. Source: Technote 1590790
The ETL or the data collection jobs are not processing data as expected.
Make sure the correct package is being run. The packages provided by the applications are specific to version. The extract, transform, and load (ETL) catalog contains the fact and dimension builds that define how the data is extracted, transformed, and loaded to the data warehouse.- Insight 1.1.1 with CLM at 3.0.1.x and JTS at 4.0.0.x in a distributed topology must use the 'new with 1.1.1' data manager ETLs for 3.0.1. The data manager ETLs that ship with Insight come in various flavors: ones that are for use with CLM 3.0.1 and ones that are for use with CLM 4.0.
- Insight 1.1.1.1 with CLM 4.0.0 and JTS is at 4.0.1 must also use the 'new with 1.1.1.1' data manager ETLs for 4.0. The data manager ETLs that ship with Insight come in various flavors: ones that are for use with CLM 4.0 and ones that are for use with CLM 4.0.1.
Not enough system resources
The ETLs are running and consuming system resources, but there is no Out Of Memory or crash occurring. This needs more investigation based on used and available system resources. The ETLs may simply be running as quickly as currently possible. For how to determine if the System needs more memory, see Does my server have enough memory?Database backups
Running a backup process during the scheduled ETL run time (by default, this is 12 AM) will also add additional load onto the database server, causing the ETLs to run longer. Ensure that no backup is being run during the ETL process.Outdated JDBC driver
The JDBC driver allows the JVM to connect to the database and transfer data and therefore directly affects the performance of the database with respect to data loading. For large datasets, the corrections in recent JDBC drivers for performance will help alleviate problems associated with moving large amounts of data. Make sure that the JDBC driver is the latest recommended version for the Database and is the correct 64 bit (or 32 bit) version. For DB2, the JDBC Driver can be referenced from DB2 Technote 1363866. An installed DB2 JDBC driver an be determined by issuing the following command from the command line:java com.ibm.db2.jcc.DB2Jcc -versionFor a DB2 JDBC driver that has not yet been installed, the information about the JDBC driver can be retrieved by running the following java command on the jar from the command line:
java -cp <jdbc driver path and file> com.ibm.db2.jcc.DB2Jcc -versionThe build number naming convention for the Db2 JDBC driver is sYYMMDD, where YY is the year, MM is the month, and DD is the day. You can view the fixes since that version by visiting DB2 Technote 1415236 and looking at the versions after the current version that is used on the system. The knowledge base for the DB2 JDBC drivers can be seen here: DB2 Technote 1358484.
Custom SQL queries are causing delays in running ETLs
In some environments, third party tools are used to gather data by running SQL queries against the database. Running these additional SQL queries will put extra load on the database server, thus causing the ETLs to run longer. Ensure that there are no custom queries running against the database during the time the ETLs run.Network delays
If there are too many network hops between the CLM Server and the database server, the latency may cause long running ETLs as the data is extracted and loaded. Ensure that your Database Server and CLM Server are located on the same network. To troubleshoot network performance, see How do I determine if my network is contributing to my performance degradation?.Database tuning
If you are using a DB2 database, start the DB2 control panel, right-click the database you want to tune, and select Design Advisor. Follow the instructions in the wizard and accept the setting values. See How do I determine if my database has performance problems? for more information.Other integrations
Other integrated applications that provide data may have performance issues affecting the ETL Data load.- In Requisite Pro, if the index RQGEN_SESSION_X for the RQGENERICTABLETEMP table is missing it may result in the ETL load being slow or having errors. See Technote 1430948 for more information.
- In Focal Point, the amount of attributes pulled may be more than necessary resulting in much larger sets of data than will be actually used on the ETL. Check the data volume of the Focal Point module. Check the number of attributes and number elements in the module. ETL may not use all the attributes of the elements that are being extracted. Identify the subset of the attributes that are used, create a view exposing only the attributes needed by the ETL, and when specifying the URLs for resources in the XDC append the view id of the newly created view so that only that subset of attributes is extracted. See Technote 1611262 for more information.
Product specific enhancements
Rational Quality Manager
- Rich Text Threshold RQM has the capacity to adjust the threshold size for processing rich text in Execution Step Results to control its performance impact for data collection jobs. The ETL processes the plain text within the rich text. By setting this threshold lower, you can speed up the performance of the ETL but, there is a balance needed between allowing the users to view all the rich text and the performance of the ETL. Added in RQM 3.0.1.3 reporting notes
- Max Feed Entries per page The setting Max Feed Entries per Page determines how many items are returned from REST per page (Maximum number of entries in a page of entries). If the value is 1, that means only 1 item is returned in each page. The page number is:
(total number)/(Max Feed Entries/Page)
This setting breaks up the data and can improve performance. However, if it is set too low (a small page size), the Jazz query service may flush the query result from the cache. By default, only 65 query results are cached for RQM 3.0.1.3. So it takes a long time to process all the pages in the feed. Again, this is a trade off between getting the data to load correctly and performance. The default setting for "Max Feed Entries per Page" is 50 for RQM 3.0.1.3. If you have a large number of steps or use an excessive number of data pools (in the thousands range), then you should use a low Max Feed Entries/Page setting. Source: Technote 1595993
Related topics:
- How to read ETL log files
- Why do my OOB ETLs take so long to run?
- Why do my custom ETLs take so long to run?
- Long-running ETLs with error(s)
- Long-running ETLs without error(s)
External links:
- None
Additional contributors: None
Contributions are governed by our Terms of Use. Please read the following disclaimer.
Dashboards and work items are no longer publicly available, so some links may be invalid. We now provide similar information through other means. Learn more here.