Introduction
The 6.0 release of IBM® Rational® Quality Manager (RQM) introduces a major new feature: configuration management. You can now manage the evolution of test artifacts using techniques similar to those which Rational Team Concert supports for managing source code. You can organize test artifacts into streams and baselines. You can easily reuse test artifacts by branching streams or baselines, and you can apply versioning across your entire CLM solution by using global configurations.
This 6.0 report focuses on the new configuration management feature. It examines how response times are impacted by when adopting configuration management. It also looks at the how response times are impacted by the number of streams or baselines.
If you are not using configuration management, please refer to
Collaborative Lifecycle management report: Rational Quality Manager 6.0 release. For more information on global configurations, please refer to
Collaborative Lifecycle Management performance report: Global configuration and back link indexing.
Standard disclaimer
The information in this document is distributed AS IS. The use of this information or the implementation of any of these techniques is a customer responsibility and depends on the customer's ability to evaluate and integrate them into the customer's operational environment. While each item may have been reviewed by IBM for accuracy in a specific situation, there is no guarantee that the same or similar results will be obtained elsewhere. Customers attempting to adapt these techniques to their own environments do so at their own risk. Any pointers in this publication to external Web sites are provided for convenience only and do not in any manner serve as an endorsement of these Web sites. Any performance data contained in this document was determined in a controlled environment, and therefore, the results that may be obtained in other operating environments may vary significantly. Users of this document should verify the applicable data for their specific environment.
Performance is based on measurements and projections using standard IBM benchmarks in a controlled environment. The actual throughput or performance that any user will experience will vary depending upon many factors, including considerations such as the number of other applications running in the customer environment, the I/O configuration, the storage configuration, and the workload processed. Therefore, no assurance can be given that an individual user will achieve results similar to those stated here.
This testing was done as a way to compare and characterize the differences in performance between different configurations of the 6.0 product. The results shown here should thus be looked at as a comparison of the contrasting performance between different configurations, and not as an absolute benchmark of performance.
Test methodology
IBM® Rational® Performance Tester (RPT) was used to simulate traffic generated from a browser client. RPT test scripts were created for each use case. The scripts are organized by pages where each page represents a user action; Tests were run with a 60 second think time between pages for each user.
The test environment is described in section
Topology and
Key configuration parameters. Test repositories were migrated from 5.0.2GA, but then the RQM projects were enabled for configuration management and additional streams and baselines were created.
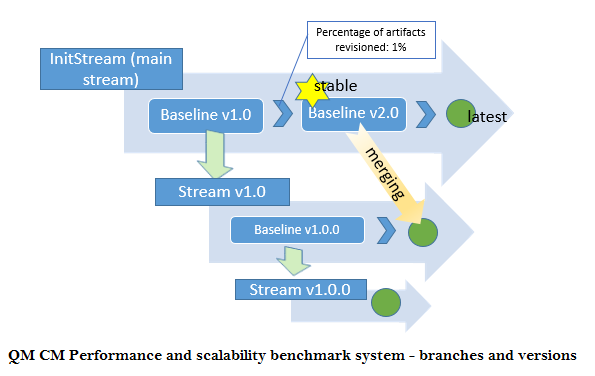
- The layout for sub-streams and baselines in the initial stream migrated is shown in the picture below
Additional details on the specific data shapes tested can be found in the
Data Volume and shape section of Appendix A.
Impact of working in streams and baselines
We conducted a series of tests to assess the impact of using the new configuration management features. We looked at common RQM "read" use cases under three different conditions:
- With configuration management disabled
- With configuration management enabled, in the context of a stream
- With configuration management enabled, in the context of a baseline. Here we looked only at read operations, since a baseline does not allow changes.
The charts below show the detailed results for a 1000 user workload in repository with 500K test artifacts. Here is a summary:
- There is a small cost to enabling configuration management. Most operations slow down slightly (< 250 ms) after enabling configuration management.
- There is an additional cost when running in the context of a baseline (as opposed to a stream) for several operations (artifact browsing, searching, and sorting). This operations can be as much as 250 ms slower in a baseline than in a stream, and as much as 500 ms slower in a baseline than with configuration management disabled.
Read operations in baseline vs stream vs opt-out
| artifact counts: 60 test plans in total; each test plan is linked to 600 test cases, and 600 test scripts 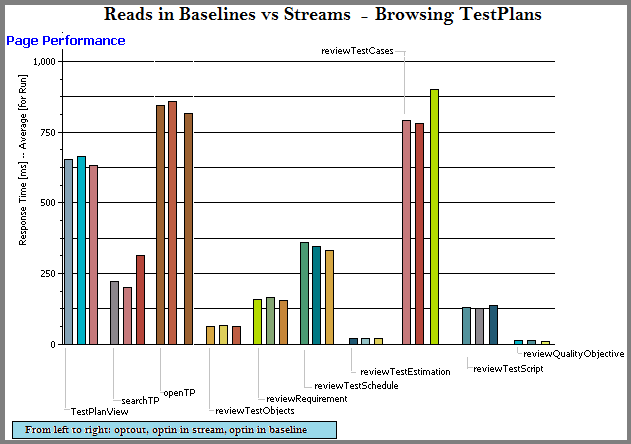
|
artifact counts: 30,000 test cases 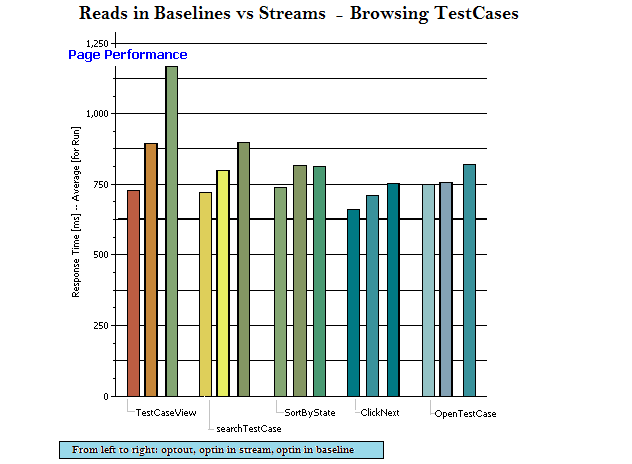
|
| artifact counts: 120,000 test case execution records 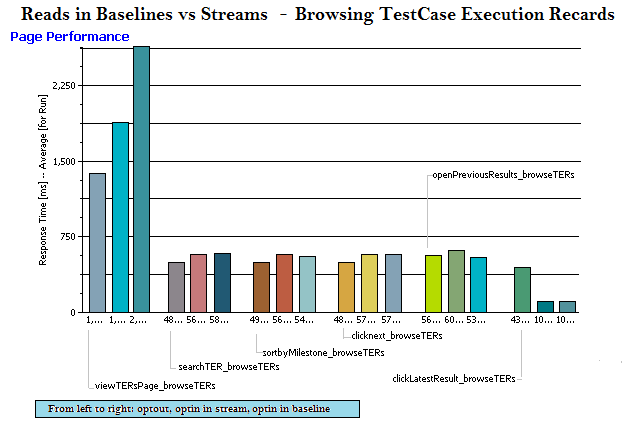
|
artifact counts: 30,000 test scripts 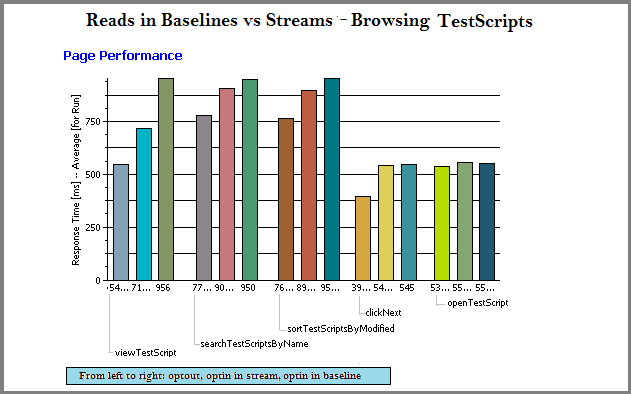
|
Impact of artifact counts
We next looked at how response times were impacted by increasing the number of artifacts. We looked at two things:
Number of streams
In this test, we created additional streams from the initial stream, to look at how response times were impacted as the number of streams increased. The initial stream contained 500,000 test artifacts (as did all of the additional streams). What we found was that:
- Create or edit operations were not impacted by the number of streams.
- Some read operations (browsing test execution records and test scripts) became slower as the number of strames increased.
Selected page response times for reads as a function of number of streams
 |
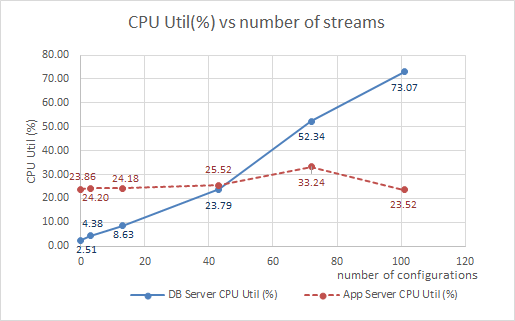
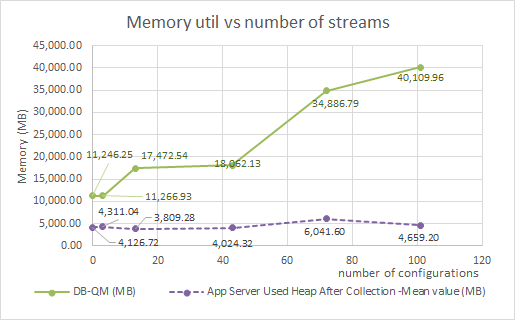
Memory and CPU usage on the database server increased as the number of streams increased.
Resource utilization as a function of number of configurations
| CPU |
Memory |
 |
 |
Total number of artifacts
In this set of tests, we looked the impact of increasing the total number of artifacts in a single QM project area, with configuration management enabled. We started with our
standard data shape of 500,000 artifacts, and expanded it to 2 million and 4 million artifacts. We ran the
1000 user workload against each of these 3 repositories, with configuration management enabled. The response times for operations are listed below.
What was found was that:
- Response times degrade as the number of artifacts in a project area increases.
- Larger repositories use more memory, CPU, and have higher disk I/O than smaller repositories
- The response times in the 4M repository have degraded to a point where that system would be difficult to use.
Size of the project area - counts for artifacts
| Count |
Size of the project area |
( approximation |
) |
| Total number of artifacts |
500K |
2M |
4M |
| Test Plans |
60 |
210 |
410 |
| Test Cases |
30K |
120K |
240K |
| Test Scripts |
30K |
120K |
240K |
| Test Case Execution Records |
120K |
480K |
960K |
| Test Case Results |
360K |
1440K |
2880K |
| Other artifacts |
34K |
130K |
260K |
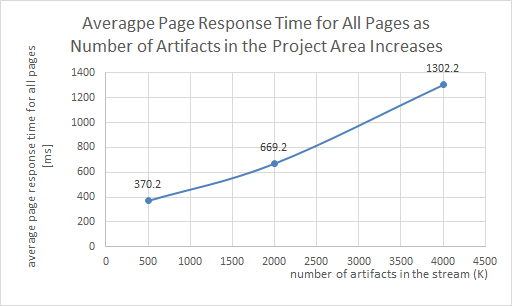
The graph below shows that the general performance degraded as the number of artifacts in the project area increased.
Average page response time for all pages as function of size of the project area
 |
From the results of the individual page performances, we found that read operations were more sensitive to the artifact counts. The following charts show groups of page response times using different project area sizes under the 1000 user performance load -
Response time charts for selected pages as function of size of the project area
| page response time comparisons |
 |
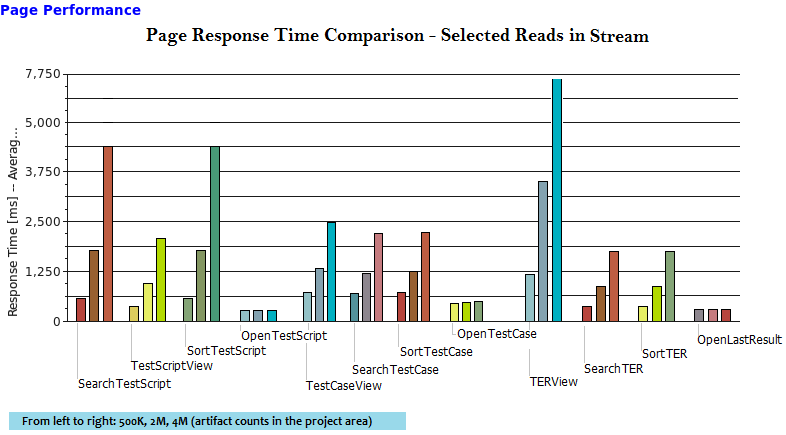 |
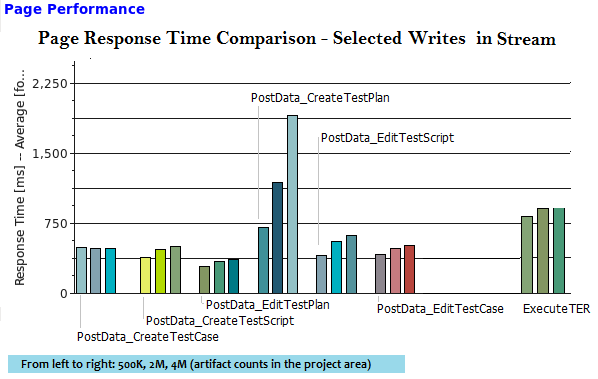 |
 |
System resource usage on both servers became bigger as the page performance degraded when the artifact counts were getting larger:
OS util as function of size of the project area
| CPU |
Disk |
Memory |
 |
 |
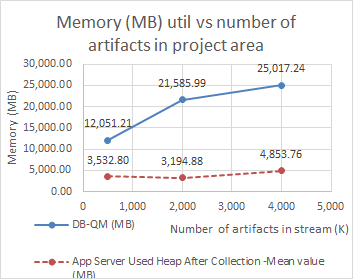 |
It was also observed that the time to create a sub-stream has increased significantly as the size of the project area grew.
Substream creation time as function of size of the project area
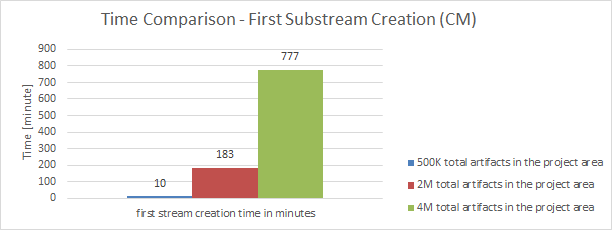 |
Appendix A:
Topology
The topology under test is based on
Standard Topology (E1) Enterprise - Distributed / Linux / DB2.
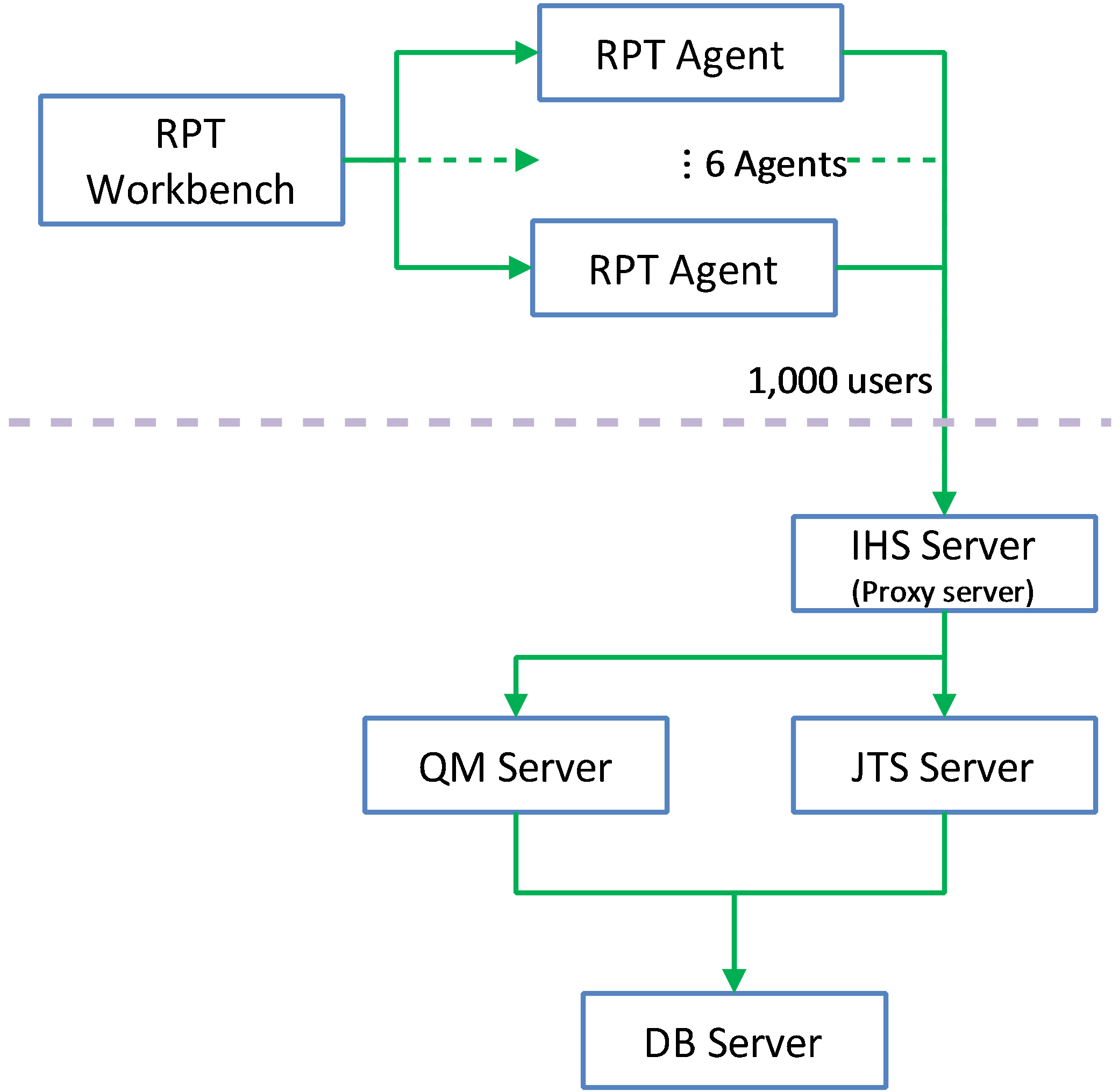
The specifications of machines under test are listed in the table below. Server tuning details listed in
Appendix B
| Function |
Number of Machines |
Machine Type |
CPU / Machine |
Total # of CPU vCores/Machine |
Memory/Machine |
Disk |
Disk capacity |
Network interface |
OS and Version |
| Proxy Server (IBM HTTP Server and WebSphere Plugin) |
1 |
IBM System x3250 M4 |
1 x Intel Xeon E3-1240 3.4GHz (quad-core) |
8 |
16GB |
RAID 1 -- SAS Disk x 2 |
299GB |
Gigabit Ethernet |
Red Hat Enterprise Linux Server release 6.5 |
| JTS Server |
1 |
IBM System x3550 M4 |
2 x Intel Xeon E5-2640 2.5GHz (six-core) |
24 |
32GB |
RAID 5 -- SAS Disk x 2 |
897GB |
Gigabit Ethernet |
Red Hat Enterprise Linux Server release 6.5 |
| QM Server |
1 |
IBM System x3550 M4 |
2 x Intel Xeon E5-2640 2.5GHz (six-core) |
24 |
32GB |
RAID 5 -- SAS Disk x 2 |
897GB |
Gigabit Ethernet |
Red Hat Enterprise Linux Server release 6.5 |
| Database Server |
1 |
IBM System x3650 M4 |
2 x Intel Xeon E5-2640 2.5GHz (six-core) |
24 |
64GB |
RAID 5 -- SAS Disk x 2 |
2.4TB |
Gigabit Ethernet |
Red Hat Enterprise Linux Server release 6.1 |
| RPT workbench |
1 |
IBM System x3550 M4 |
2 x Intel Xeon E5-2640 2.5GHz (six-core) |
24 |
32GB |
RAID 5 -- SAS Disk x 2 |
897GB |
Gigabit Ethernet |
Red Hat Enterprise Linux Server release 6.4 |
| RPT Agents |
6 |
VM image |
4 x Intel Xeon X5650 CPU (1-Core 2.67GHz) |
1 |
2GB |
N/A |
30GB |
Gigabit Ethernet |
Red Hat Enterprise Linux Server release 6.5 |
| Network switches |
N/A |
Cisco 2960G-24TC-L |
N/A |
N/A |
N/A |
N/A |
N/A |
Gigabit Ethernet |
24 Ethernet 10/100/1000 ports |
N/A: Not applicable.
vCores = Cores with hyperthreading
Network connectivity
All server machines and test clients are located on the same subnet. The LAN has 1000 Mbps of maximum bandwidth and less than 0.3 ms latency in ping.
Data volume and shape
The artifacts were migrated from 5.0GA repository which contains a total of 579,142 artifacts in
one large project.
The repository contained the following data:
- 60 test plans
- 30,000 test scripts
- 30,000 test cases
- 120,000 test case execution records
- 360,000 test case results
- 3,000 test suites
- 5,000 work items(defects)
- 200 test environments
- 600 test phases
- 30 build definitions
- 6,262 execution sequences
- 3,000 test suite execution records
- 15,000 test suite execution results
- 6,000 build records
- QM Database size = 12 GB
- QM index size = 1.5 GB
User roles, test cases and workload characterization
User Roles
| Use role |
% of Total |
Related Actions |
| QE Manager |
8 |
Test plan create, Browse test plan and test case, Browse test script, Simple test plan copy, Defect search, View dashboard |
| Test Lead |
19 |
Edit Test Environments, Edit test plan, Create test case, Bulk edit of test cases, Full text search, Browse test script, Test Execution, Defect search |
| Tester |
68 |
Defect create, Defect modify, Defect search, Edit test case, Create test script, Edit test script, Test Execution, Browse test execution record, Switch to configuration (CM), Baseline reads (CM), Compare configurations (CM) |
| Dashboard Viewer |
5 |
View dashboard(with login and logout) |
| Release Manager |
Single user |
Merge changes from a baseline (CM) |
Test Cases
| Use Role |
Percentage of the user role |
Sequence of Operations |
| QE Manager |
1 |
Test plan create:user creates test plan, then adds description, business objectives, test objectives, 2 test schedules, test estimate quality objectives and entry and exit criteria. |
| 26 |
Browse test plans and test cases: user browses assets by: View Test Plans, then configure View Builder for name search; open test plan found, review various sections, then close. Search for test case by name, opens test case found, review various sections, then close. |
| 26 |
Browse test script: user search for test script by name, open it, reviews it, then closes. |
| 1 |
Simple test plan copy: user search test plan by name, then select one, then make a copy. |
| 23 |
Defect search: user searches for specific defect by number, user reviews the defect (pause), then closes. |
| 20 |
View Dashboard: user views dashboard |
| Test Lead |
8 |
Edit Test Environment: user lists all test environments, and then selects one of the environments and modifies it. |
| 15 |
Edit test plan: list all test plans; from query result, open a test plan for editing, add a test case to the test plan, a few other sections of the test plan are edited and then the test plan is saved. |
| 4 |
Create test case: user create test case by: opening the Create Test Case page, enters data for a new test case, and then saves the test case. |
| 1 |
Bulk edit of test cases: user searches for test cases with root name and edits all found with owner change. |
| 3 |
Full text search: user does a full text search of all assets in repository using root name, then opens one of found items. |
| 32 |
Browse test script: user search for test script by name, open it, reviews it, then closes. |
| 26 |
Test Execution: selects View Test Execution Records, by name, starts execution, enters pass/fail verdict, reviews results, sets points then saves. |
| 11 |
Defect search: user searches for specific defect by number, user reviews the defect (pause), then closes. |
| Tester |
7 |
Defect create: user creates defect by: opening the Create Defect page, enters data for a new defect, and then saves the defect. |
| 4 |
Defect modify: user searches for specific defect by number, modifies it then saves it. |
| 13 |
Defect search: user searches for specific defect by number, user reviews the defect (pause), then closes. |
| 5 |
Edit test case: user searches Test Case by name, the test case is then opened in the editor, then a test script is added to the test case (user clicks next a few times (server size paging feature) before selecting test script), The test case is then saved. |
| 3 |
Create test script: user creates test case by: selecting Create Test Script page, enters data for a new test script, and then saves the test script. |
| 7 |
Edit test script: user selects Test Script by name. test script then opened for editing, modified and then saved. |
| 41 |
Test Execution: selects View Test Execution Records, by name, starts execution, enters pass/fail verdict, reviews results, sets points then saves. |
| 6 |
Browse test execution record: user browses TERs by: name, then selects the TER and opens the most recent results. |
| 9 |
Compare configurations: user selects a target configuration and a source configuration, and compares
|
| Dashboard Viewer |
100 |
View dashboard(with login and logout): user logs in, views dashboard, then logs out. This user provides some login/logout behavior to the workload |
| Release Manager |
100 |
Merge changes from a baseline: user selects a target stream and a source baseline, compares these configuration, and merges a testplan from the list of difference
|
Appendix B: Key configuration parameters
Product
|
Version |
Highlights for configurations under test |
| IBM HTTP Server for WebSphere Application Server |
8.5.0.1 |
IBM HTTP Server functions as a reverse proxy server implemented via Web server plug-in for WebSphere Application Server.
Configuration details can be found from the CLM infocenter.
HTTP server (httpd.conf):
OS Configuration:
- max user processes = unlimited
|
| IBM WebSphere Application Server Network Deployment | 8.5.0.1 | JVM settings:
- GC policy and arguments, max and init heap sizes:
-Xgcpolicy:gencon -Xmx8g -Xms8g -Xmn2g -Xss786K
-Xcompressedrefs -Xgc:preferredHeapBase=0x100000000 -verbose:gc -XX:+UseParallelGC
-Xverbosegclog:gc.log -XX:MaxDirectMemorySize=1G
Thread pools:
- Maximum WebContainer = Minimum WebContainer = 500
OS Configuration:
System wide resources for the app server process owner:
- max user processes = unlimited
- open files = 65536
|
| DB2 |
ESE 10.1.0.3 |
*For large repository, increase the following values: APPLHEAPSZ, LOGFILSIZ, LOGPRIMARY, and LOGSECOND |
| LDAP server |
|
|
| License server |
|
N/A |
| RPT workbench |
8.3.0.3 |
Defaults |
| RPT agents |
8.3.0.3 |
Defaults |
| Network |
|
Shared subnet within test lab |
Appendix C: Enabling configuration management (CM) for QM
Please refer to the article
Collaborative Lifecycle Management performance report: Global configuration and back link indexing for information on what to expect when first activating the configuration management feature, and for information the performance of linking scenarios test artifacts and other tools like IBM Rational DOORS Next Generation or IBM Rational Team Concert.
Appendix D: System resource usage - with and without configuration management enabled
For a standard 500K repository under load
Resource utilization
Resource utilization for 6.0 - with vs without CM
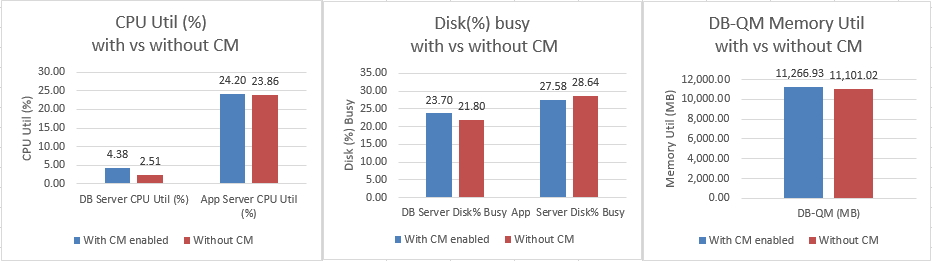 |
Garbage collection - JVM GC Chart
For JVM parameter please refer to
Appendix A
Verbose garbage collection is enabled to log the GC activities. These GC logs showed very little variation between runs. There is also no discernible difference between versions. Below is one example of the output from the GC log for each application.
QM WAS server - with vs without CM
| With CM enabled |
Without CM enabled |
 |
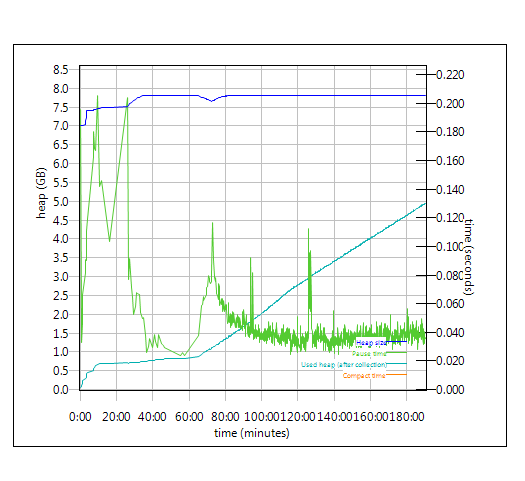 |
JTS WAS server - with vs without CM
| With CM enabled |
Without CM enabled |
 |
 |
For more information
About the authors:
HongyanHuo
Related topics:
Questions and comments:
- What other performance information would you like to see here?
- Do you have performance scenarios to share?
- Do you have scenarios that are not addressed in documentation?
- Where are you having problems in performance?
Warning: Can't find topic Deployment.PerformanceDatasheetReaderComments