Sizing ELM deployments for 7.x releases
Authors: VaughnRokosz Build basis: ELM 7.x Date: August 2024Introduction
Whether new users or seasoned experts, customers using IBM Engineering Lifecycle Management (ELM) products all want the same thing. They want to use the ELM products without worrying that their deployment implementation will slow them down, and that it will keep up with them as they grow. That desire leads to a few basic questions:- What kind of hardware is required to run ELM?
- What are the best deployment topologies for that hardware?
- For any given class of hardware, how many users and how much data can be supported?
Standard disclaimer
The information contained in this article is derived in part from data collected from tests performed in IBM test labs under controlled conditions. Customer results may vary greatly. Sizing does not constitute a performance guarantee. IBM assumes no liability for actual results that differ from any estimates provided by IBM.Factors that influence performance
Before getting into the details of system specifications, it is worth discussing the general factors that influence performance. These factors will help you put the later guidance into context and also help you understand whether you should make adjustments for your specific environment.The factors are:
- Deployment topology. How many servers will be deployed, and what are the specifications of the servers (memory, number of CPUs, disk I/O speed)?
- Data. How big is the deployment (how many artifacts and of what kind)? At what rate is the deployment growing, as people, custom scripts or integrations create more artifacts?
- Application usage. How many people are actively using the system at any one time? What are those people doing? Are there integrations or custom scripts in use that should be accounted for in the usage model? At what rate are new users onboarded to the deployment?
Impact of deployment topology
You can find more information on deployment topologies on the standard deployment topologies overview page. There are three main deployment types:- A departmental topology, which is the minimum IBM recommends for any production deployment. This topology minimizes the amount of hardware required and is best for smaller projects and smaller-sized teams.
- An enterprise topology, which is useful for medium-size to large-size teams. This topology spreads the workload across additional servers in order to support larger teams.
- A federated topology, which is useful for very large enterprises that deploy an ELM solution per product line or organizational division, but would still like to be able to have a program-wide view of their entire portfolio of work.
Impact of processor count
The number of active users that can be supported by a deployment is most strongly influenced by the number of available CPUs. Imagine a case where a user is interacting with an ELM application through the browser, and makes a selection in the UI that runs an operation on the server. That operation will use one CPU. If 200 users were running operations on the server at the same time, that would require 200 CPUs. If the server doesn't have enough CPUs available, the server would be running at 100% CPU and the user operations would slow down. Real users, of course, don't run operations continuously. They think about what they are seeing on the screen, or they get coffee or attend meetings. So a workload of 200 active users doesn't really need 200 processors - that's just the worse case. But the basic principle applies: more active users requires more CPUs. A special case is users that are accessing the system through application programming interfaces (APIs). If you develop code to interact with a deployment via APIs, that code will put more load on a deployment than a real user. For sizing purposes, think of each API user as the equivalent of 20 real users. Refer to the section on Integrations and APIs for more information. CPUs can be added in one of three ways:- An individual server can be given more processors
- Applications can be separated onto their own servers, which in effect increases the total number of available processors by adding more machines
- Applications can be clustered, which increases the available processors by having multiple cluster nodes
Impact of memory
The reliability of a ELM deployment is most strongly influenced by the available RAM. Without enough memory, the applications can hang, crash or become slow. You'll need to allocate enough RAM to satisfy the primary consumers of memory on a ELM server, which are:- The memory heap for the Java run-time environment that is running the application
- Native memory used by the Java run-time (especially critical for network operations involving file transfers)
- Memory used by the operating system.
- If the JVM heap is not large enough or is not tuned correctly, system performance can be degraded by garbage collection.
- If there is too much demand for memory, the operating system's file cache may shrink and this can impact the caching of data stored locally on the application servers.
- High memory usage may result in swapping to disk, which degrades performance.
Impact of data (repository size)
The size of your repository can impact performance, and can influence the hardware requirements needed to deliver good performance. Repository size refers to two different things:- The number of artifacts of each particular type (e.g. how many work items, how many test cases, how many requirements). This is the repository size.
- The structure of those artifacts and the relationships between them (e.g. work items can be associated with a development plan, test cases can be associated with a test plan, requirements can be added to a module, artifacts can reference each other via links). This is the repository shape.
- The full-text index (used for artifact searching) grows as artifacts are added. More memory is needed to cache the files associated with the full-text index.
- The database tables which store data grow as the number of artifacts grows. Larger databases require more memory on the database server.
- Native Java memory (specifically, direct memory buffers) is used by the Web application servers to send information over the network to browsers (or EWM Eclipse clients). The source code management features in EWM can be particularly impacted by the size of source files, the number of files in a workspace, and frequency at which workspaces are refreshed (such as through builds).
- Java heap memory is used to carry out ELM operation. Larger repositories result in more data being transferred from server to client, which then requires additional memory in the ELM application servers. As the memory demands on the Java heap grow, performance can degrade if garbage collection gets triggered more frequently. There can also be high transient demands on memory (e.g. when running reports which return large result sets).
Sizing ELM deployments
The sizing approach used in this article uses a simplified model that looks at two dimensions:- Deployment sizing
- Machine size
| Size | Active Users | Total Database size |
|---|---|---|
| Small | 10 | Up to 50G |
| Medium | 10-250 | Up to 250G |
| Large | 250-500 | Up to 1TB |
| Extra-large | >500 | >1TB |
An active user is defined as a person that is interacting with with the system and is therefore sending requests to the applications. A registered user is a person that is able to access the system. The important dimension to the sizing is the number of active users - you can have a much higher number of registered users. A registered user only starts to consume system resources once they become active. The definition of an active user explicitly excludes user ids used by scripts or automation. Scripts usually place a much higher load on a system than real people. For planning purposes, consider each API user as the equivalent of 20 real people.
These size buckets are per-application. For example, a medium size deployment of EWM can support up to 250 users with an EWM database of up to 250G. A large deployment of ETM would support up to 500 users with an ETM database of up to 1TB. You could have a medium EWM server and a large ETM server in a single deployment. The standard server sizes used are:
- 2 vCPU/4G RAM
- 4 vCPU/8G RAM
- 8 vCPU/16G RAM
- 16 vCPU/32G RAM
- 48 vCPU/96G RAM
- 64 vCPU/128G RAM
- JTS: Jazz Team Server
- JAS: Jazz Authorization Server
- GCM: Global Configuration Management
- EWM: Engineering Workflow Management
- ERM: Engineering Requirements Management DOORS Next
- ETM: Engineering Test Management
- DCC: Data Collection Component (part of Jazz Reporting Service)
- RB: Report Builder (part of Jazz Reporting Service)
- LQE rs: Lifecycle Query Engine (Relational store)
- LDX rs: Link Index Provider (Relational store)
- PUB: PUB Document Builder
- ENI: Engineering Lifecycle Optimization - Engineering Insights
Sizing an enterprise topology
IBM's recommendation for an enterprise topology is to deploy each application onto its own server. The recommended sizing for each application server is listed in the table below.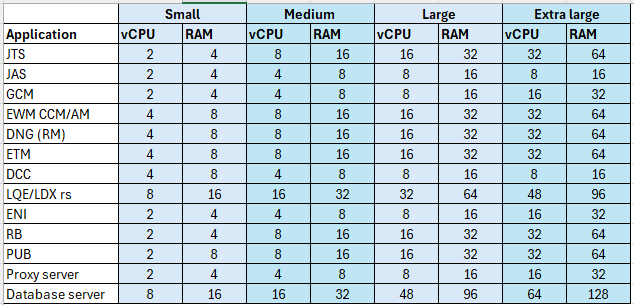 Here are the principles behind these sizings:
Here are the principles behind these sizings: - More vCPUs are required to support more active users.
- More RAM is required to support more data.
- The database is used by all servers so it needs to be larger. The database requires more memory as a deployment grows.
- Plan to have multiple database servers in larger deployments.
- In 7.1, the LDX and LQE servers use the database server for storage. However, memory is still required for indexing. IBM recommends using a single LQE rs system to support both reporting and link indexing, so the LQE rs server is larger than other servers.
- You should expect to cluster the EWM and ETM servers in the extra-large deployment. You may also need to deploy multiple ERM servers as the repository grows.
- The Jazz Authorization Server does not require significant resources.
- You may need multiple proxy servers for redundancy, or more vCPUs for higher user loads. A single proxy with 8 vCPUs can become overloaded for transaction rates in the 500-1000 per second range.
Sizing a departmental topology
A departmental topology uses fewer servers and hosts multiple applications per server. IBM recommends using such a topology for small and medium deployments only. Use the sizing estimates from the enterprise topology and sum up the vCPU and RAM requires for each hosted application. For the standard departmental topology, the system requirements would be: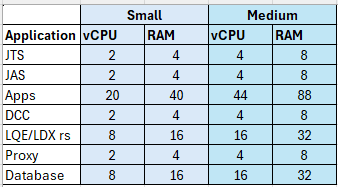 Here, "Apps" refers to the ELM applications hosted on a single server: EWM, ETM, ERM, JTS, ENI, PUB and GC.
Here, "Apps" refers to the ELM applications hosted on a single server: EWM, ETM, ERM, JTS, ENI, PUB and GC.
Proof-of-concept sizing
A proof-of-concept (or evaluation) topology can be used for extra-small deployments:- Less than 10 total concurrent users
- Less than 100,000 total artifacts
| Application | vCPU | RAM |
|---|---|---|
| JTS | 2 | 4 |
| JAS | 2 | 4 |
| Apps | 8 | 24 |
| DCC | 4 | 8 |
| LQE/LDX rs | 8 | 16 |
| Proxy | 2 | 4 |
| Database | 4 | 12 |
It is possible (although not recommended) to further combine applications so that you end up with a 3 system deployment:
| Application | vCPU | RAM |
|---|---|---|
| JTS/JAS/Apps/Proxy | 8 | 32 |
| DCC/LQE/LDX rs | 8 | 32 |
| Database | 4 | 12 |
Special considerations
This section discusses additional factors that can impact deployment sizing.Storage
There are two factors to consider when addressing storage needs:- How much disk space is needed for each application?
- How fast does that storage need to be?
Artifact counts and repository size
The sizing model is based on the size of the application databases. If you are planning a new deployment, you might find it easier to estimate the number of artifacts. As a rule of thumb, assume that 1 million artifacts will require 50G of database storage. If you have enabled configuration management, then assume 50G per 1 million versions. This applies to ETM, EWM/RMM and ERM. LQE rs will use more disk space since it will read data from all applications (as will LDX rs). LQE rs also keeps track of the versions associated with each configuration (stream or baseline), and the space required for that is based on the number of versions per configuration times the number of configurations. To estimate LQE rs database size, use the following guidelines:- 12G per million resources indexed
- Add .5G per million versions added for configurations
Older components using Jena
Older versions of some components use a triple-store database (based on Jena technology), and this will grow as artifacts are created. The components which are most impacted by the size of the triple-store are:- The Lifecycle Query Engine (prior to 7.0.3)
- The Link Index Provider (LDX) - prior to 7.1
Considerations for database servers
Database servers benefit from additional RAM as repositories grow. Both Oracle and Db2 use memory to cache information, so when you have more RAM, you have the ability to cache more data (which can then speed up SQL queries). If you share a single database server between the ELM application servers, the memory demands on the database server are a function of the combined load across all application servers. If your deployment will host millions of artifacts across multiple applications like EWM, ETM, and ERM - then you should deploy database servers with 64G or more of memory. Large and extra-large deployments can usually benefit from higher amounts of database memory (e.g. 756G or more). Large and extra-large deployments may require multiple database servers.Integrations and APIs
The ELM suite provides a set of application programming interfaces (APIs) that allow for the development of custom applications that interact with the ELM applications. These custom applications can place extreme load on an ELM deployment, depending on how the APIs are used. A custom application that calls the APIs in multiple threads with no throttling can easily add load that is equivalent to 1000 real users. IBM recommends that you implement a governance process around API usage. Specific recommendations:- Maintain an inventory of API-based tools, and understand the load that each tool places on the ELM applications. In the absence of other information, assume that each API thread in a tool is equivalent to 20 real users. Add this adjusted user count to your active user totals when sizing your ELM servers.
- Register and monitor each tool as a custom expensive scenario
- Test integrations at scale under load in a test environment (using production-like data)
- Create a change control board (CCB) to manage integrations and approve their deployment (as well as to manage changes to integration tools)
- Have throttling in place to control the load from tools and adjust their load based on system conditions
Data collection Component
The Data Collection Component is not strongly impacted by deployment size. It has a fixed number of threads, and does not handle concurrent user load. A 4 vCPU/8G system will typically be enough to manage collection of data from the applications. If you increase the default number of threads, or you have additional data sources to index (e.g. because you've deployed additional application instances), you might need up to 8vCPU/16G of RAM.Clustering
Extra-large deployments should consider clustering when supporting more than 500 users. Clustering in ELM 7.1 is supported in these places:- Engineering Test Management
- Engineering Workflow Management (and Rhapsody Model Manager)
- Jazz Authorization Server
- Oracle (with RAC) and Db2 (with PureScale)
- A distributed cache manager (DCM)
- Eclipse Amlen
| Size | DCM | Amlen |
|---|---|---|
| Large | 8 vCPU, 8G RAM | 1 instance: 8 vCPU, 16G RAM, 64G disk |
| Extra Large | 16 vCPU, 16G RAM | 2 instances: 8 vCPU, 16G RAM, 64G disk |
Additional sizing information for Eclipse Amlen can be found here. Clustering is not supported by other parts of the ELM suite. However, you can deploy additional application instances and spread out the load that way. That includes:
- Setting up new ERM servers
- Adding Report Builder instances
- Adding new LQE or LDX servers to support a subset of applications
Networking
The sizing model discussed in this document does not address networking considerations. IBM assumes the following things to be true:- Application servers and database servers are located within a single data center with low latency between all servers (e.g. <1 ms).
- There is sufficient network bandwidth to support data transfer rates
- The quality of service on the network is high (no packet retries)
- There are no devices on the network that interfere with communication (e.g. by artificially causing socket timeouts)
Operating system
The choice of operating system (Windows or Linux) does not impact the sizing recommendations.References
- Scaling the Configuration-aware Reporting Environment
- Setting up an EWM and ETM clustered environment
- Planning the installation of Eclipse Amlen
- Deployment planning and design
- Standard deployment topologies overview
- Engineering Lifecycle Management Architecture Overview
- Deployment Monitoring
- Performance sizing guides and datasheets
- Engineering Lifecycle Management API Landing page
- Queries for determining repository size and shape


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
Dept.png | manage | 9.8 K | 2024-09-11 - 18:50 | VaughnRokosz | |
| |
SizingTable.png | manage | 29.7 K | 2024-09-30 - 16:38 | VaughnRokosz |
{kind=link}
{kind=link}
Contributions are governed by our Terms of Use. Please read the following disclaimer.
Dashboards and work items are no longer publicly available, so some links may be invalid. We now provide similar information through other means. Learn more here.