Page contents
- Monitoring resource-intensive scenarios
- Custom scenarios
- Common scenarios
- Rational DOORS Next Generation
- Enabling suspect traceability (No longer applicable to the v7.0 release and beyond)
- Running RPE/RRDG reports with a large result set
- Importing a large number of requirements
- Exporting a large number of requirements
- Using view query with large result sets
- Running DNG ETL jobs to populate the data warehouse
- Rhapsody Model Manager
- Rational Team Concert
- Comparing a repository workspace to a stream with which it is extremely out-of-date
- Annotating an extremely large text file
- Importing a Microsoft Project plan with large number of tasks
- Exporting a large number of work items to a Microsoft Project plan
- Adding many build result contributions to a build result
- Loading a large plan
- Collecting build engine metrics
- Rational Quality Manager
- Jazz Reporting Services (all reporting technologies)
- Global Configuration Management
This page aims to capture user and system scenarios across the ALM portfolio that can potentially drive relatively higher load on a Jazz application. Such scenarios can lead to server debt (such as out-of-memory errors) if they are run during peak times on systems that don't have sufficient spare resources available. These scenarios are qualified or quantified to make them easier to understand. Where possible, best practices are provided that can minimize or avoid the issue altogether.
This list starts with the assumption that the applications are being run in a standard topology and on servers that are sized and tuned following our recommendations.
Consider these scenarios:
[1] Built-in properties or characteristics that limit the scenario (defaults shown in parentheses); see the scenario for further details.
[2] When advanced logging is enabled for a scenario, this information is included.
[3] These scenarios also include start and stop logging (not advanced logging) by the remote applications when carrying out their part in these distributed scenarios.
- User scenarios known to ALWAYS have high demands. They tend to be computationally expensive or use/consume large amounts of data/memory. They can lead lead to system slow down, and on resource-constrained servers, have been known to bring down environments. Examples: Large BIRT reports, builds, high volume imports.
- User scenarios known to SOMETIMES have high demands. Their resource consumption or computation demands tend to be more reasonable and manageable. With appropriate system resources, system configuration guidance, or usage best practices, their impact could be mitigated or avoided. Examples: Plan loading, populating a dashboard.
- System scenarios with POTENTIAL high impact. Examples: ETL jobs, backup, online migration.
| Table 2: Throttling and Logging by Scenario | ||||
| Scenario ID | Throttling[1] | Advanced Logging[2] | ||
|---|---|---|---|---|
| Run_Data_Validation | NA | NA | ||
| Collect_Item_Count_Metrics | NA | NA | ||
| Collect_Project_Metrics | NA | NA | ||
| Gathering_Monitoring_Data_And_Applying_Rules | NA | NA | ||
| DNG_Suspect | NA | NA | ||
| DNG_Report | RDMPublishReportsRunners (3) | Report name, Project Area, Component, Global/Local Configuration, Module/Requirement Set | ||
| DNG_Import | ReqIF.importThreadPoolSize (1) | ReqIF filename/path, Project Area, Component, Local Configuration | ||
| DNG_Export | ReqIF limited by # cores on DNG server. CSV limited by "CSV Export Page Size" and "Export page sleep duration" | ReqIF Definition, Project Area, Component, Global/Local Configuration | ||
| DNG_Query | query.client.timeout (30 seconds), SPARQL Query abort timeout (5 min), query load management | Query (RQL or Module/View/Filter), Project Area, Component, Global/Local Configuration | ||
| DNG_ETL | NA | NA | ||
| RMM_Index_Large_Deliveries | Large change set delivery threshold (number of files) | Logging of change set processing steps | ||
| RTC_Compare_Workspace | Maximum limit of SCM workspace compare scenarios (0) | Workspace, Stream, Project Area | ||
| RTC_Annotate_File | Maximum size of a File that can be annotated = 1GB | Filename/path, file size, workspace, Project Area | ||
| RTC_MSP_Import | NA | Filename/path, Project Area, Plan name | ||
| RTC_MSP_Export | NA | Project Area, Plan | ||
| RTC_Add_Build_Contribution | NA | Build engine, Build definition, Build result label, contribution added, Project Area | ||
| RTC_Load_Plan | delayed child loading | Plan name, Plan view, Project Area | ||
| RTC_Build_Engine_Queue_Metrics | NA | NA | ||
| RQM_Duplicate_Test_Plan | NA | Plan name, 'include links' setting, Source/Target Project area, Component, Global/Local configuration | ||
| RQM_Bulk_ArchiveDelete | NA | Project Area, Component, Configuration, Query context (i.e. description of artifacts to archive/delete) | ||
| RQM_Export_Pdf | NA | File name, Export Type (PDF or CSV), Project Area, Export Job UUID, Export request time | ||
| RQM_Export_Csv | NA | File name, Export Type (PDF or CSV), Project Area, Export Job UUID, Export request time | ||
| JRS_BIRT | NA | Report name, Report runtime settings (as applicable) Project area, Component, Configuration | ||
| JRS_DCC | job schedule | NA | ||
| JRS_EXECL_EXPORT | job schedule | NA | ||
| JRS_LQE_Maintenance | NA | NA | ||
| JRS_LQE_Query | LQE query limits | Sparql Query executed (from LQE Admin UI), Report Builder Report name (if contains advanced query) | ||
| JRS_Refresh_Data_Source | metamodel.autorefresh.time (6am), metamodel.autorefresh.repeat.inminutes (720) | NA | ||
| GCM_Create_Stream | NA | Project Area, Component, Stream, Baseline [3] | ||
| GCM_Stage_Baseline | NA | Project Area, Component, Stream [3] | ||
| GCM_Create_Baseline | NA | Project Area, Component, Stream [3] | ||
| GCM_Update_Stream | NA | Project Area, Component, Stream, Baseline [3] | ||
Monitoring resource-intensive scenarios
Starting in v6.0.3, starting and stopping of resource-intensive scenarios are captured in their respective application logs. If advanced logging is turned on (managed by the new Serviceability tab for each application), then additional information about the scenario occurrence is logged. Further, new JMX MBeans track the occurrence of the scenarios as well and can be captured by enterprise monitoring tools for further analysis and trending. To enable MBeans for scenarios, edit the serviceability property com.ibm.team.repository.service.internal.serviceability.MetricsCollectorTask by setting the Enable Scenario Metrics MBean value to True, and the Enable Scenario Details MBean to True.Custom scenarios
In addition to out of the box scenarios, there are cases where custom utilities, built on available application APIs, can become a potential resource-intensive scenario. For example a custom Java script or a plugin making REST APIs call to a CLM application. Such custom functionality needs to be monitored and tracked as resource-intensive. The technique for doing so is documented in Register Custom Scripts As a Resource Intensive Scenario.Common scenarios
Data validation
Data validation is a scheduled background task that is run on each application server to perform data integrity checks against the database to identify inconsistencies. This scenario exercises the online verify functionality in the product. As part of this process the registered verifiers might make a lot of queries against the database, resulting in high I/O, memory, and CPU load on the database server and also adding more network I/O between the server and the database. Keep the frequency setting at the default setting, so only one data validation task runs at a time.Item count metrics
This operation collects detailed item counts and item size information from the repository, which help you understand data growth and data distribution patterns. This scenario walks through all the repository item states in the Item states system table to produce details about each type of item. As part of this the scenario, the operation makes a lot of queries against the database, resulting in high I/O, memory, and CPU requirements on the database server and also adding more network I/O between the server and the database. Keep the frequency setting at the default setting. It only runs once at a time. Note for v6.0.3, the default frequency for this scenario is every 15 minutes, which is too frequent; when enabling this MBean, set the "Delay Between Invocations" property to "604800" seconds (1 week) for the "CommonMetricsCollectorTask".Project metrics
This operation collects different project area specific from the repository that help identify and understand data growth and data distribution patterns, e.g. count of team areas, work items, streams, baselines, components, etc. Some data collection related to project sizing (captured as of 6.0.5) involve queries that put heavy demand on the database and drive significant load on the database server, thus potentially impacting response times for any application with databases on that database server.Data collector task
The DataCollector is a new microservice in 6.0.6.1 that runs externally and queries CLM applications to get data from enabled JMX MBeans to store in .csv files for later visualization. This microservice is part of a new CLMMon utility used to capture time series data to aid IBM Support in problem determination. Note this scenario does not appear on the application serviceability tab but will be counted by the resource-intensive scenario MBeans.Rational DOORS Next Generation
Enabling suspect traceability (No longer applicable to the v7.0 release and beyond)
Link validity and suspect links are capabilities you can use to monitor related information for updates. When dependencies change (such as a customer requirement) you need a way of marking related information as "suspect" so that it can be reviewed and updated as appropriate. Suspect links and link validity offer very similar functions but under very different circumstances. Suspect links describe related information within a single context, whereas link validity is used with configuration management. Because of the approach used for local indexing of suspect links, you should be aware that you need to consider their resource overhead on the server when deploying that functionality. The performance of suspect traceability and link validity depends on the number of artifacts, concurrent users, and the rate of change activity. Often it is turned on without understanding what it does, how it will be used, or the cost of doing so.Best practices
Regular use in production during normal hours should be limited to small deployments, when the server is lightly loaded, or only when necessary, otherwise you risk driving load on the server. When suspect tracking is enabled, a full reindex occurs up front (see Suspicion Indexing). When you enable suspect traceability (in a project that is not enabled for configuration management), an index of change information for all link types, artifact types, and attributes is automatically built. Don't turn it off and then on again, because this action will cause another full reindex. Instead, pause the indexing (by using the Suspicion Profile Settings for the Requirements Management page). By default, the index is automatically refreshed with new changes every 60 seconds, but you can change that setting. If you lower the default refresh setting, a greater load is placed on the server. For the refresh setting, use a number that is 30 seconds or higher. These best practices don't apply to projects with configuration management enabled, in which case link validity, not suspicion profiles, provides the capability to note changes in requirements.Running RPE/RRDG reports with a large result set
Generation of poorly constructed RPE/RRDG reports that include a result set of over 5K requirements can be slow. Concurrent generation of PDF reports for modules including more than 5K requirements should be limited to generating only one PDF at a time. DNG has the advanced property "RDMPublishReportsRunners", which defaults to 3 and constrains the number of RPE/RRDG reports that can be generated concurrently.Best practices
Be sure to test reports in advance with near production equivalent data. Where possible, define the report with JRS. Also see the general reporting best practices.Importing a large number of requirements
Importing can be computationally expensive. At the end of an import, when all indexing occurs, the import can block other user activity. Imports of 10K requirements or less should be fine. DNG currently limits how many ReqIF imports occur at once through the "ReqIF.importThreadPoolSize" advanced property, which defaults to 1. If the ReqIF import thread limit is reached you can still submit additional import requests. You will get the status message "Waiting for the completion of {N} previously submitted ReqIF Import Tasks."; you can close the import dialog box to let this continue in the background.Best practices
For large (10K or greater) imports, we recommend importing during off hours or when the system is lightly loaded.Exporting a large number of requirements
Export is less of a problem with CSV or ReqIF exports. Note that the number of concurrent ReqIF exports is limited to the number of virtual cores on the DNG server. Similar to the ReqIF import, when the export limit is reached,you get a status message and can let the export continue in the background. Large Word or PDF exports can be problematic and should be limited to one at a time when exporting more than 10K requirements. Two properties can govern the behavior of CSV exports. "CSV Export Page Size" limits the number of export entries (rows) that DNG builds at a time. "Export page sleep duration" causes DNG to pause between export page processing so that the export doesn't overload the server when doing a large scale export.Best practices
We recommend exporting during off hours for large (10K or greater) exports to Word or PDF. Inclusion of Comments in exports have been known to be expensive and should be avoided.Using view query with large result sets
Browsing artifacts and modules in DNG is done in the context of a view using a query (based on filter settings) to populate the contents of the view. Large view queries resulting in 10K or more requirements can be resource-intensive, especially across multiple folders or if you are filtering based on strings, dates, or links. Traceability queries are even more resource-intensive. DNG uses the "query.client.timeout" advanced property to limit the run time of view queries; it defaults to 30 seconds. The "SPARQL Query abort timeout (in ms)", which defaults to 5 minutes, will limit most queries that are not limited by "query.client.timeout" value (such as loading the folder structure). Some query scenarios not governed by these timeouts include TRS, suspect indexing (when the suspect data is deleted upon "untracking" or rebuilding the index), building the type system, recent feeds (e.g. comments, requirements). As of 6.0.3, DNG includes a query load management mechanism to proactively manage and monitor the load resulting from view queries. Finally, in 6.0.6 ifix003, a new Long running query monitor was added which will automatically kill any SPARQL queries not configured to run over a specific period of time.Running DNG ETL jobs to populate the data warehouse
This is a more of a system initiated operation and is a function of repository size and the amount of change. Generally for repository sizes greater than 100K-200K it is best to run the ETL jobs during off hours. Alternatively, use DCC to populate the data warehouse. This doesn't apply to configuration management enabled projects that populate the LQE database instead of the data warehouse.Best practices
For large repository sizes, containing more than 100K-200K artifacts, it is best to run the ETL jobs during off hours.Rhapsody Model Manager
Large change set deliveries
Subsequent to delivery of a change set, RMM will perform indexing of all resources included in the delivered change set. Should the change set be large, the subsequent indexing could take some time to complete which could slow other deliveries and their subsequent indexing. The default size for considering a delivery large is 1000 resources which is configurable by changing the RMM advanced property "Large change set delivery threshold (number of files)". If a delivery is that size or higher, then the scenario is identified as expensive and will be logged (and appropriate expensive scenario counters incremented). Deliveries smaller than that size are not tracked. If advanced logging is enabled, the application will log the details of the change set processing steps, e.g. parsing and indexing, that are performed.Rational Team Concert
Comparing a repository workspace to a stream with which it is extremely out-of-date
This could cause server issues if a large number of these types of comparisons happen concurrently. As of 5.0.1,you can set a server property to limit the number of comparisons that can happen at the same time (maximum limit of SCM workspace compare scenarios). This value defaults to 0, which allows unlimited comparisons. When limited, the compare operations are queued until other compares finish. The user will see a slower compare or, in the extreme case where the thread waits too long, the compare will fail after 15 minutes (this limit is not configurable).Best practices
When a workspace compare is performed, the service IFileSystemService#compareWorkspace is called. Occurrences of these calls are listed in the active services page of the CCM application. Should there be a large number of calls appearing at once, you may want to limit the number of workspace compares by setting the "Maximum limit of SCM workspace compare scenarios" advanced property to 25% of the available CPU cores.Annotating an extremely large text file
Annotating files with sizes in the multi-gigabyte range have been known to cause out of memory issues since the annotate operation puts all contents, file, history, etc, in memory, large files, especially with large history, and can require significant memory. As of 6.0.3, a configuration parameter, "Maximum size of a File that can be annotated" exists and defaults to 1GB to reduce the likelihood of this issue occurring.Importing a Microsoft Project plan with large number of tasks
How long an import takes depends on the number of items in the plan and their nested structure. For example, an import from a Microsoft Project file containing 2000 tasks could take up to 30 minutes on the first import and 8-10 minutes on subsequent imports, depending on server configuration and load. Consider also the memory demands of an import that will take approximately 100KB for each task being imported over and above the memory needed for typical RTC operations. In most cases, import of Microsoft Project plans happens infrequently, generally at the start of a project. However, if imports are to be a frequent occurrence, be sure that the server memory allocation has ample spare capacity. Note that the numbers provided are based on testing in a non-production environment.Best practices
If your Microsoft Project file contains more than 1000 tasks, we recommend you import or export during off-hours or when the server is lightly loaded.Exporting a large number of work items to a Microsoft Project plan
Similar to an import, export time and load depend on the size and complexity of the plan. The impact is primarily to memory on the server.Adding many build result contributions to a build result
When a large number of contributions (compilation contributions, JUnit tests, downloads, log files, links, work item references, and so on) are included in a build result, because of the way they are stored (in a single data structure), the server could spend a lot of time marshalling and unmarshalling the persisted contributions when adding or deleting contributions. At best this is a slow running operation, however, should there be a large number of concurrent builds performing similar work (adding many build result contributions), the potential for impact to the server increases.Best practices
Keep build result contributors to a minimum. If you are using an external build tool, such as Build Forge or Jenkins that is integrated with RTC, keep the overlap between build results in both tools to a minimum, and where there is overlap, consider storing only in the external build tool. Publish large contributions as links not the actual content, that is, publish download files greater than 10MB by using the "artifactLinkPublisher" task instead of "artifactFilePublisher". See Publishing build results and contributions for a full list of tasks, some of which have a "link" instead of a "content" version.Loading a large plan
The RTC plan editor provides users with great flexibility to display plans in customized and flexible configurations. In order to provide rapid display of custom plan configurations, the RTC planning editor must fetch all the details of each work item when loading plans. Consequently, when the scope of a plan includes a large number of work items, loading of such plans can drive server load. We have greatly improved plan loading performance with each release by deferring the loading of out placed "child" work items or by allowing users to turn on and configure server side plan filtering to avoid loading work items that will never be displayed in plans.Collecting build engine metrics
RTC provides a JMX MBean for collecting metrics on the status of the build engines for an RTC server. The collection operation iterates through all the build engines in the repository and categorizes the number of responsive and unresponsive engines. It provides the following number of build engines in total and that are responsive, unresponsive, responsive busy, responsive idle, unresponsive busy (in progress builds but did not contact within the monitoring time), active and inactive. This data is useful to determine if the build engines in the build farm are over or under utilized. Gathering this data requires execution of several database queries, this scenario could put more load on the database server thereby impacting its response time thus ability for the RTC server to respond to user and other requests.Best practices
If the repository has more than a few hundred build engines and the Build Engine Metrics MBean is enabled, then increase the delay between invocations of the BuildQueueMetricsCollectorTask.Rational Quality Manager
Duplicating test plans with a large test hierarchy
The impact of duplicating a test hierarchy depends on the number of items and their size, and whether you choose to copy referenced artifacts. A test plan might include multiple child test plans, each with its own test cases and test scripts, resulting in potentially thousands of artifacts, each of which could reference a large amount of content storage. Although you can count the number of objects ahead of time, you cannot determine the overall memory size of the selected hierarchy. Because the duplication occurs in a single transaction, it can require a high amount of memory to complete. See Copying huge Test Plan brings server down with Out of Memory errorsBest practices
A best practice is not to do a deep copy and, instead, only copy references to test cases, test scripts, etc. Should a deep copy be needed, break down the overall hierarchy duplication into smaller subsets. If that is not possible, it is best to perform the operation when the system is more lightly loaded and, increase the available system memory, or both. An even better best practice is to move away from duplication altogether in support of reuse by clone and own. Instead, transition to use of Configuration management in the QM application.Bulk archiving or deletion of test results
If you select more than 10000 artifacts to archive or delete in bulk, the operation can take a long time and might time out. See Web browser-based artifact deletes greater than around 10,000 items will fail to execute.Best practices
Either select one page of results at a time or ensure that fewer than 10,000 artifacts are included in the result set, that is, work with smaller sets of assets.Exporting test artifacts to PDF (as of 7.0.1)
The impact of exporting test artifact(s) to a PDF report depends on the number of associated artifacts and the type of export job. An artifact might include multiple associated artifacts, each with its own associated artifacts. For example, should you select a test plan for export to a PDF report, the test plan might be associated to multiple ETM and cross-product artifacts, each with its own associations, resulting in potentially thousands of artifacts to export. This operation can take a long time to be completed and could impact other export jobs in the queue.Best practices
Avoid use of the Export Comprehensive option when the Export Summary option suffices. When the Export Comprehensive option must be used, if the export will include more than 1000 artifacts, it is better to run them during off-peak hours as it can take a long time to complete.Exporting test artifacts to CSV (as of 7.0.1)
The impact of exporting the details of a test artifact list view to a CSV report depends on the number of associated artifacts that appear in the list view. For example, when you export the list view of test plans to a CSV report, the report will contain the data from all the columns and rows in the list view. Selecting specific rows or hiding columns does not affect the exported data. This operation can take a long time to be completed and can impact other export jobs in the queue.Best practices
Before exporting artifacts to CSV, first filter the view by creating a query that reduces the number of artifacts in the list view. An export with more than 10000 artifacts will consume large amount of time, it is better to run them during off-peak hours.Jazz Reporting Services (all reporting technologies)
Running BIRT reports based on live data
Reports on live data run more slowly than those using the Data Warehouse or LQE, which are optimized for reporting. In addition, custom BIRT reports can be inefficient in their construction or pull large volumes of data, increasing load. Each of the applications has an advanced server property, "Maximum Record Count", that limits the number of rows a report can fetch. Any report passing that limit will fail. The default is -1 which leaves the report unconstrained. The setting should not be used as a solution to bad behaving reports. It is rather a way to discover bad behaving reports as they will fail to render when they go past the limit.Running Excel export on large reports
The Excel export creates an Excel document containing the query results from a report. Depending on the number of rows in the report this can take both time and disk space, as the data is written to temp files before being combined into the final Excel document.Best practices
Schedule large export jobs to run during off-hours or when server load is light, and frequently clearing /tmp/ReportBuilder/ExportData while also ensuring disk space is below 80%. Metamodel refresh will also clear the temporary export data automatically.Running DCC jobs that require high storage and processing power
Most Data Collection Component jobs can run at regular intervals, obtaining a delta of changes from the previous run. However, a few DCC jobs involve a larger amount of data, and place higher demands on storage and processing power on the DCC server. Because DCC shares the same data warehouse as the applications, load on the DCC processing these jobs with intensive storage and processing demands, could affect the applications:- Activity Fact Details (Activity History)
- Build Fact Details (Build History)
- File Fact Details (File History)
- Project Management Fact Details (Project Management History)
- Quality Management Fact Details (Quality Management History)
- Requirement Management Fact Details (Requirement Management History)
- Request Management Fact Details (Request Management History)
- Task Fact Details (Task History)
- Jazz Foundation Services (Statistics)
Best practices
Schedule the identified jobs to run during off-hours or when server load is light. (Note: Job names listed are based on v6.0.2; where different, the names for earlier releases is in parentheses). Data job counter information can be seen under Scenarios on the https://<your-server>/dcc/service/com.ibm.team.repository.service.internal.counters.ICounterContentService. MBeans for the scenario can be enabled in the serviceability property com.ibm.team.repository.service.internal.serviceability.MetricsCollectorTask by setting the Enable Scenario Metrics MBean value to True, and the Enable Scenario Details MBean to True.Performing LQE index maintenance
Backup, compaction, re-indexing, and addition or removal of data sources can drive load on LQE. In the case of reindexing, there will also be a heavy, resource consuming process, potentially causing the application server to slow down due to the data being indexed. For example, if you're reindexing the DNG Resources, then you will expect to exert a load on to the DNG application server too.Best practices
Schedule these scenarios during off-hours or when server usage is light.Running high-volume and very complex queries
High-volume and very complex queries can put a heavy load on the data source. As indicated above, ensure your reports return only what is necessary for the report consumer. In the Advanced section of the Report Builder users can edit the queries generated by Report Builder, or write custom SQL (Data Warehouse) or SPARQL (LQE) queries for a report. However, after a query has been edited, you can no longer use other Report Builder functions with that report. Inexperienced users can easily write and run an inefficient or incorrect query that could cause the data source to become unresponsive. For LQE, you can set query service properties, such as the result limit (the default is 3000 results) and query timeout (the default is 60 seconds). LQE limits SPARQL queries based on these settings. Note that these limits do not apply to SPARQL queries against metadata.Best practices
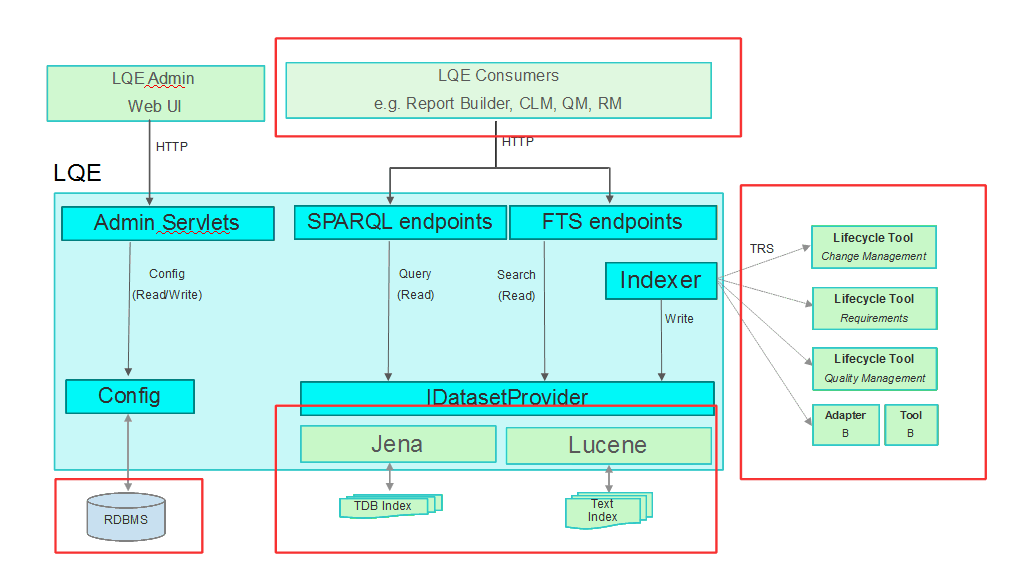
LQE offers a simple query interface in its Administration UI. You can use this interface to run sample queries to discover information and improve your queries. You can also copy SPARQL queries from the Advanced section in Report Builder into this interface and make small changes to debug issues. This UI can target different scopes or configurations, or all data. Be aware that queries run from this UI still impact the data source, and are subject to the LQE Query Service limits, as described above. Access to LQE data sources can be restricted. For more information on improving LQE performance, see Monitoring and managing the performance of Lifecycle Query Engine and Improving Lifecycle Query Engine performance.Refreshing a data source in Report Builder
When a refresh of a data source is initiated from the Report Builder administrator UI, the data source is queried for the latest metadata. This can increase demand on both LQE and Report Builder servers and impact the performance of other reports that are running. This is especially true for LQE data sources, where most of the metadata must be queried (whereas most of the data warehouse metadata is hard-coded in Report Builder which is not possible to do so for LQE). Many factors affect how long a refresh takes: the number of project areas, the complexity of their data model (for example, a large number of enumeration values), and the amount of change. If a refresh is in progress, when a user accesses the Report Builder UI, a message displays and the user must wait until the refresh completes. To better understand the data flow in and out of LQE, including refresh of data sources, reading from and populating the indices, see LQE Data Flows. Note that the metadata refreshes are included in the TRS feeds from the applications.Best practices
Report Builder refreshes the data sources when the server starts. It also runs a background job twice daily to automatically refresh all data sources. Configure the refresh to run at times when your organization has a lighter load, using the following properties in the server/conf/rs/app.properties file:- metamodel.autorefresh.time=6\:00AM
- metamodel.autorefresh.repeat.inminutes=720
Global Configuration Management
Network Considerations
Operations on global configurations such as the ones described here involve making multiple network requests. If the network has high latency, and the global configuration has a large number of contributions, the operation can take a long time to complete even if the load on each server is low.Creating streams in a global configuration hierarchy
When viewing a global configuration stream, you can multi-select any number of baselines contributing to that stream and create new streams for those baselines all at once. These can include local application baselines as well as global baselines. Global streams will automatically be created for any global baselines above the selected baselines as well. The time to generate the streams depends on the depth of the global configuration hierarchy, the number of local application (DNG, RQM, and DM) baselines in the hierarchy, and number of versioned artifacts in each. Because the local application (DNG, RQM, DM) creates its streams, most of the demand is placed on those servers. If there are a large number of baselines to create in the application servers, or if the GCM hierarchy is very deep, you might want to create the new streams during a period of light usage. You can also create fewer streams at once by selecting fewer initial baselines and creating streams in smaller batches. Or, you can first create local streams in their respective applications, then use the "Replace" action in GCM to replace those local baselines with streams you've already created.Creating a baseline staging stream from a global stream hierarchy
When you create a baseline staging stream (BSS) for a global configuration hierarchy, you also create a new baseline staging stream for each global stream in the hierarchy. The time to do this and the load on the GCM application depends on the number of global configurations in the hierarchy, how deeply nested they are, and the number of custom properties and links they have.Creating a global baseline from a global stream hierarchy
Global baselines can be created directly or through use of a baseline staging stream. First, when creating a new global baseline directly without explicit use of a baseline staging stream, the original stream is untouched, and a new baseline hierarchy is created by requesting baselines for each local configuration from the contributing application (DNG, RQM, or DM) and creating global baselines for each global configuration in the hierarchy. Much of the processing is done by the contributing application servers (DNG, RQM, and DM). If there are many local configurations, a given applications load could be high.Updating a global stream from a baseline
When you update a global stream to match a baseline, every nested baseline in the hierarchy is examined and compared against the equivalent nested baseline of the target baseline. Several changes can then occur in the stream to add, remove, and replace nested baselines. The time required to update the global stream depends on the size and complexity of the configuration hierarchy, and the number of differences between the source stream and the target baseline Most of the demands for this action is placed on the GCM server. If updating a very large stream, you might want update the stream during a period of light usage.

| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
LQEDataFlows.png | manage | 36.5 K | 2016-05-19 - 21:19 | TimFeeney | Illustrates data flow in/out of LQE |
{kind=link}
{kind=link}
Deployment.CLMExpensiveScenarios moved from Deployment.CLMExpensiveOperations on 2016-05-11 - 08:46 by TimFeeney -
Contributions are governed by our Terms of Use. Please read the following disclaimer.
Dashboards and work items are no longer publicly available, so some links may be invalid. We now provide similar information through other means. Learn more here.