Page contents
This scenario tests the performance of the Enterprise Dependency Based Build feature under a high volume workload, simulating concurrent build operations that developers would execute in a real case scenario.
The tests scenario themselves are based on observations of the usage performed by our customers and our recommended practices to them.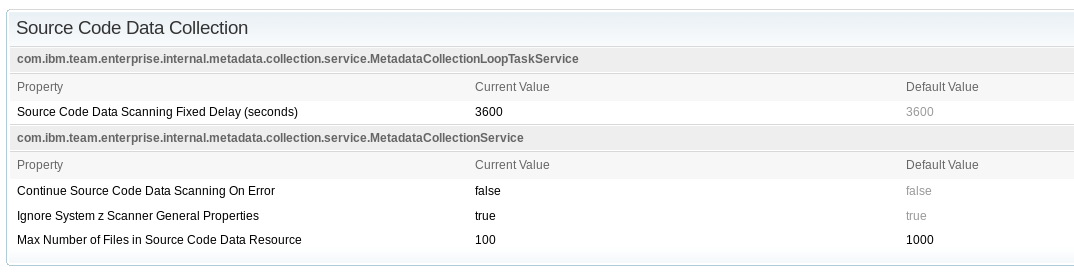

These are used in the testing framework to emulate real users operations at the load and rates finer specified later in this topic:


3 streams will have 3 concurrent developers with the following roles and files to be modified in each iteration:
5 streams will have 1 developer assigned: 1:1 relationship between developers and streams:
Additionally, one team build will be requested at every hour for each of the streams: not scheduled to start at same hour every time but with a difference of 10 minutes., so not all the team builds are executed at same hour time.
5 streams will have 6 concurrent developers with the following roles and files to be modified in each iteration:
3 streams will have 3 developers assigned: 1:1 relationship between developers and streams:
Repeating the role steps at cycles of 30 minutes. Additionally, one team build will be requested at every hour for each of the streams: not scheduled to start at same hour every time but with a difference of 10 minutes., so not all the team builds are executed at same hour time.
The tests scenario themselves are based on observations of the usage performed by our customers and our recommended practices to them.
Scenario Detailed Description
The scenario presents the following situation: enterprise deployment of Rational Team Concert. Several development teams work in building different applications (COBOL/CICS applications). Each team has a development integration stream for consolidating their work and building changes in a regular basis. The idea is to try to mimic a real case scenario usually found in the field where we see a Project Area representing a "program" (group of applications), and different teams which can map to business units develop their own application. Different roles have been considered in the tests automation to reflect different sort of changes, and also to consider the load that either a developer or a different kind of role would impose by modifying work items. Note that this concept of business units related development teams can be mapped to other organizations that divide them in a per-Project Area basis (instead of teams); this is still valid where the actual focus of the test is in the load that the level of changes and builds concurrency imposes, and how the server reacts; where logical teams-projects variances do not represent a matter of concern.RTC Parametrization
This section describe any parameters different from the default ones, which are relevant for the execution of the tests.RTC Server Configuration Options
The following configuration properties values have been set at server level:- Set advance property: 'Consider only outgoing change sets in personal builds = true'
- Customization of the Asynchronous Task Pool Size parameter for the amount of concurrent builds that will be executed.
- Source Code Data Collection: customize the Max Number of Files in Source Code Data Resource parameter to a maximum value of 100:
RTC Test Assets Configuration
Different RTC elements are created to execute the activities and load expected. The following is a collection of the relevant parameters that have been set in these elements:- Personal builds requested will have the Minimum Load option set
- Several streams are used in these tests. These streams have not been generated using the Duplicate stream feature. Duplicating a stream causes the Source Code Data to be reused, while for the tests information gathering it is preferred that every stream has different set of SCD.
- System Definitions: 4.0.3 Link-edit feature will not be used.
- Build Engines configuration: Build engines should be configured in such a manner that it is assured that a team build request doesn't impact personal builds concurrency. To accomplish that, the following property is added to the build engines that will be serving personal builds: requestFilter with value personalBuild=true:
Test Assets Preparation
In addition to configuring the RTC elements that will be used in the test to support the behavior; the test framework assets have to be configured as well in order to make them reproduce the activities and load expected. There are two important configuration areas to consider: (a) the emulated/virtual users; and (b) how the data was initialized in RTC.Virtual Users Characterization
To emulate the load and the main tasks expected during real solution usage, the following roles and operations have been identified.These are used in the testing framework to emulate real users operations at the load and rates finer specified later in this topic:
| Activities\Role | Developer A | Developer B | Contributor |
|---|---|---|---|
| Change a COBOL program Check-in the changes Request Personal Build to verify changes Accept incoming changes Deliver the change sets |
Change a copybook source Check-in the changes Request Personal Build to verify changes Accept incoming changes Deliver the change sets |
Log in to repository Create and save a work item Execute a query (25% of times) -- just execute query every 4 iterations Logout |
Scenario execution preparation
Following are the main steps for preparing the environment for the test scenario run. The steps are beyond creating and configuring the assets already described:- Assign/verify Build System definitions with sample resources
- Perform a full build of the applications
- Load the virtual developers workspaces in preparation for the test run.
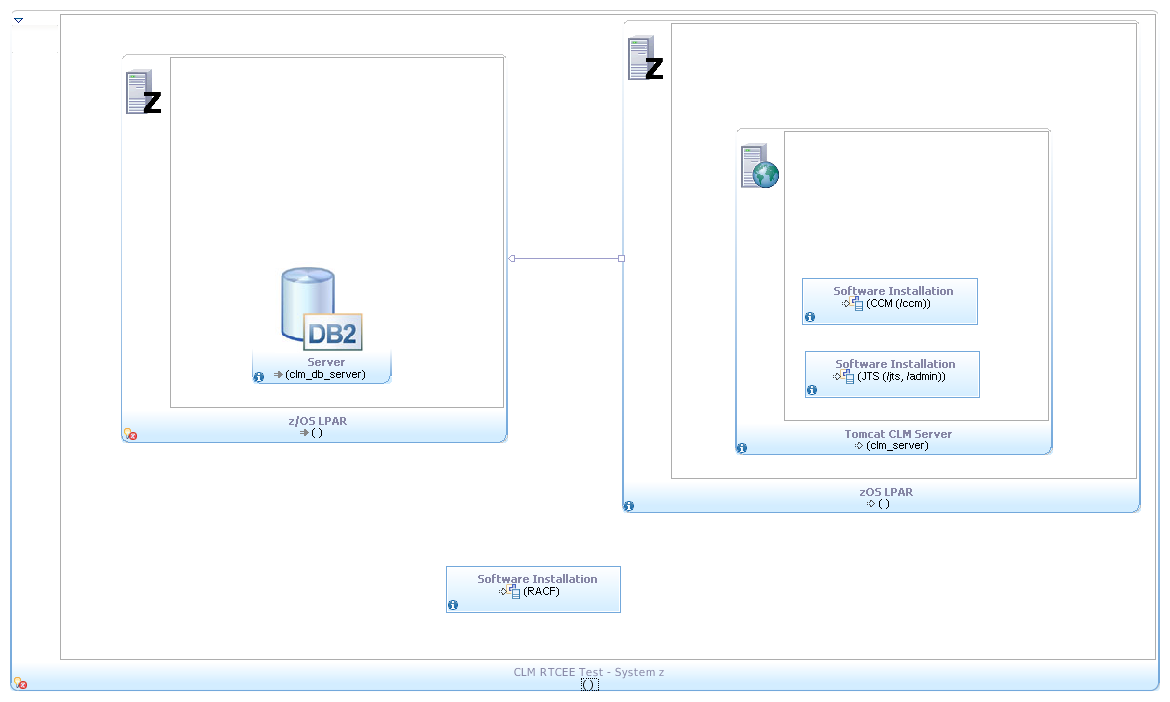
Test Topologies
The following topologies are being used for the execution of this scenario in order to test the performance and gather relevant data.Dual Tier Topology: z/OS
Test Data
From the existing scalability test data based on Mortage Application sample, the following will be used: 500 times replication of Mortage Application sample.| Assets | Overall dev assets |
|---|---|
| 3000 COBOL programs 2000 Copybooks 1000 BMS 3 others |
6003 |
Scenario Variances
Based on the previous detailed configuration, two variances of the scenario are tested:Test Scenario 1
The following SCM structure is used:- 50 components distributed among 25 streams
- Each stream will hold 2 of the components with the test data sample distribution: one component will hold the common project of called MortgageApplication-Common, where the other component contains the rest of projects
- 30 build engines targeting the same build agent. This will allow the concurrency described later and the team builds execution.
- 25 build engines will be configured to just accept personal builds
- One build definition for each stream representing the build of the test data application
- Each stream will have a team build with associated:
- A build workspace
- A defined HLQ and load directory for every team / build definition
- Each stream will have a team build with associated:
- Each virtual user will need to have defined:
- A personal repository workspace flowing to the assigned stream
- A personal HLQ and load directory on the build machine
- Personal workspace, HLQ and load directory will be used in the automated build requests processing
- The emulation will try to reproduce a scenario during a work day and variations of work load to different applications and streams. Similar to what would be normal lifecycle of development enterprise work, where some applications are more active than others.
- From the 25 defined streams, 10 would be identified as more active ones, with users and load described in next subpoints.
- Simulation of 28 concurrent developers work.
- Following distribution of emulated developers and streams:
| Role | #users | Files to modify (1 line per developer) |
|---|---|---|
| Developer role A | 6 (per stream) | AAACMORT.cbl / AABCMORT.cbl / AACCMORT.cbl AADCMORT.cbl / AAECMORT.cbl / AAFCMORT.cbl AAGCMORT.cbl / AAHCMORT.cbl / AAICMORT.cbl AAJCMORT.cbl / AAKCMORT.cbl / AALCMORT.cbl AAMCMORT.cbl / AANCMORT.cbl / AAOCMORT.cbl AAPCMORT.cbl / AAQCMORT.cbl / AARCMORT.cbl |
| Developer role B | 1 (per stream) | AAAMLIS.bms / AAAMTCOM.cpy / AABMLIS.bms / AABMTCOM.cpy |
| Role | #users | Files to modify (1 line per developer) |
|---|---|---|
| Developer role A | 2 (per stream) | AAACMORT.cbl / AABCMORT.cbl / AACCMORT.cbl AADCMORT.cbl / AAECMORT.cbl / AAFCMORT.cbl |
| Developer role B | 1 (per stream) | AAAMLIS.bms / AAAMTCOM.cpy / AABMLIS.bms / AABMTCOM.cpy |
| Role | #users | Files to modify (1 line per developer) |
|---|---|---|
| Developer role A | 1 (per stream) | AAACMORT.cbl / AABCMORT.cbl / AACCMORT.cbl |
Additionally, one team build will be requested at every hour for each of the streams: not scheduled to start at same hour every time but with a difference of 10 minutes., so not all the team builds are executed at same hour time.
Test Reports
Information about the results of this test can be found in this topic .Test Scenario 2
The following SCM structure is used:- 150 components distributed among 25 streams:
- Each stream with 6 components with the test data distribution, using a different set of qualified file names
- 60 build engines targeting the same build agent. This will allow the concurrency described later and the team build.
- 50 build engines will be configured to just accept personal builds
- Three build definitions for each stream for building each set of the testing data
- Each stream will have a team build with associated:
- Build workspace
- Defined HLQ and load directory for every team / build definition
- Each stream will have a team build with associated:
- Each virtual user will need to have defined:
- A personal repository workspace flowing to the assigned stream
- A personal HLQ and load directory on the build machine
- Personal workspace, HLQ and load directory will be used in the automated build requests processing
-
- From the 25 defined streams, 11 would be identified as more active ones, with users and load described in next subpoints.
- Simulation of 75 concurrent developers.
- Following distribution of emulated developers and streams:
| Role | #users | Files to modify (1 line per developer) |
|---|---|---|
| Developer role A | 9 (per stream) | AAACMORT.cbl / AABCMORT.cbl / AACCMORT.cbl AADCMORT.cbl / AAECMORT.cbl / AAFCMORT.cbl AAGCMORT.cbl / AAHCMORT.cbl / AAICMORT.cbl AAJCMORT.cbl / AAKCMORT.cbl / AALCMORT.cbl AAMCMORT.cbl / AANCMORT.cbl / AAOCMORT.cbl AAPCMORT.cbl / AAQCMORT.cbl / AARCMORT.cbl AAQCMORT.cbl / AARCMORT.cbl / AASCMORT.cbl AATCMORT.cbl / AAUCMORT.cbl / AAWCMORT.cbl AAXCMORT.cbl / AAYCMORT.cbl / AAZCMORT.cbl |
| Developer role B | 3 (per stream) | AAAMLIS.bms / AAAMTCOM.cpy / AABMLIS.bms / AABMTCOM.cpy AACMLIS.bms / AACMTCOM.cpy / AADMLIS.bms / AADMTCOM.cpy AAEMLIS.bms / AAEMTCOM.cpy / AAFMLIS.bms / AAFMTCOM.cpy |
| Role | #users | Files to modify (1 line per developer) |
|---|---|---|
| Developer role A | 5 (per stream) | AAACMORT.cbl / AABCMORT.cbl / AACCMORT.cbl AADCMORT.cbl / AAECMORT.cbl / AAFCMORT.cbl AAGCMORT.cbl / AAHCMORT.cbl / AAICMORT.cbl AAJCMORT.cbl / AAKCMORT.cbl / AALCMORT.cbl AAMCMORT.cbl / AANCMORT.cbl / AAOCMORT.cbl |
| Developer role B | 1 (per stream) | AAAMLIS.bms / AAAMTCOM.cpy / AABMLIS.bms / AABMTCOM.cpy AACMLIS.bms / AACMTCOM.cpy / AADMLIS.bms / AADMTCOM.cpy |
| Role | #users | Files to modify (1 line per developer) |
|---|---|---|
| Developer role A | 3 (per stream) | AAACMORT.cbl / AABCMORT.cbl / AACCMORT.cbl |
Repeating the role steps at cycles of 30 minutes. Additionally, one team build will be requested at every hour for each of the streams: not scheduled to start at same hour every time but with a difference of 10 minutes., so not all the team builds are executed at same hour time.
Related topics:
External links:
Additional contributors:
Contributions are governed by our Terms of Use. Please read the following disclaimer.
Dashboards and work items are no longer publicly available, so some links may be invalid. We now provide similar information through other means. Learn more here.