multiple files with the same name but different functionality and impactanalysis
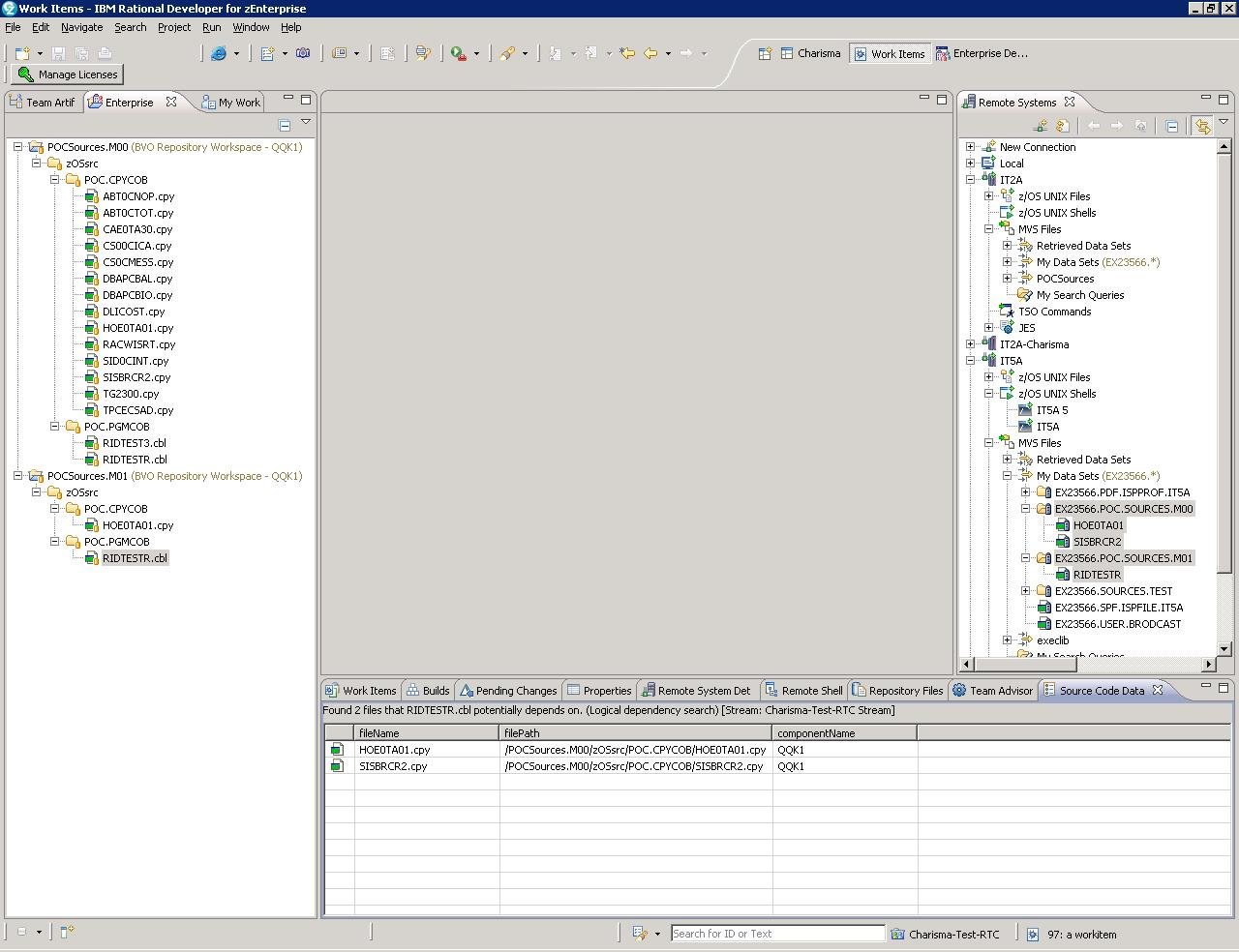
I'm having sources with the same name but different functionality for which I created separate zProjects in a zComponent. Both projects contain RIDTESTR.cbl and a copybook HOE0TA01.cpy
POCSources.M00 points to a PDS named POC.SOURCES.M00
POCSources.M01 points to a PDS named POC.SOURCES.M01
After changing RIDTESTR.cbl in POCSources.M01 and launching a build, I see that the wrong copybook is taken into consideration: the one from POCSources.M00.
Also, if I check dependencies RIDTESTR.cbl in M01 using the impactanalysis, I see the source code scanners point to the wrong copybook. The copybook from POCSources.M01 seems to be skipped completely.
Do you have any idea what is going wrong here?
Can the path to the source been taken into consideration?
Regards,
Bernd.
Accepted answer
You say the following:
POCSources.M00 points to a PDS named POC.SOURCES.M00
POCSources.M01 points to a PDS named POC.SOURCES.M01
Do you mean that is where you imported the source from? Or that is where you're loading the source to during the build process? I'm wondering if you're using the same data set definitions for both projects, i.e. you have one data set definition for COBOL source code that you have associated with both POCSources.M00/zOSsrc/POC.PGMCOB and POCSources.M01/zOSsrc/POC.PGMCOB and one data set definition for COPYBOOKs that you have associated with both POCSources.M00/zOSsrc/POC.CPYCOB and POCSources.M01/zOSsrc/POC.CPYCOB. This would mean that your source from both projects will end up loading to the same data set during the build, and the program that builds second will clobber the program that built first.
I would question why it is that you have two files with the same name but different functionality. If you can't get around this, you will need to set up different system definitions to build the two programs properly. You will need at a minimum two COBOL source data set definitions and two COPYBOOK data set definitions so that the files don't collide and so that you can point at the two different copybook data sets at build time as appropriate. The path for the copybooks is configured in the DD concatenations table in the COBOL compiler translator. Presumably you have a SYSLIB entry that includes your data set definition for your copybooks. You'd need to either use two different translators, each configured to use a different copybook data set definition, or you would need to use a build property to specify the copybook data set definition and set this value on the language definition (which in turn implies you need two different language definitions for your two cobol programs).
When you run an impact analysis to see what copybooks a COBOL program depends on, the tool will find all of the logical dependencies (e.g., A.cbl depends on copybooks X and Y), and then for each logical dependency find all of the files in the stream that satisfy that dependency. If you do the Advanced impact analysis and apply a search path, the tool will then go to the appropriate translator and see which of the candidate files comes first in the path. In your case, I believe both copybooks are tied as far as position in the path since their folders are associated to the same data set definition and it is non-deterministic (or at least not by design) which one wins.
Note that you would not have these issues if your duplicate files were in separate streams being built by different build definitions with different HLQs.
Comments
Hi Robin,
Thanks for your help.
I use POC.SOURCES.M00 and POC.SOURCES.M01 to load the sources to the host. I defined a dataset for each, but I'm reusing language definitions (“cobolsources” and “copybooks”).
We are having multiple sources with the same name but different functionality because we are dealing with multiple customers who will be migrated to a single RTC-instance.
I changed the configuration and created two separated streams as you are suggesting as well. I doublechecked the buildresult and it looks as I intended it to be.
The option to pass the translator as a build-option was not possible (I can select one in the UI, but it is not taken into account in that same UI), so I used separate language definitions each using a dedicated translator, each pointing to a dedicated dataset.
Regards,
Bernd.
Bernd,
It sounds like you were hitting the problem described in RTC 4.0 RC5 - zOS and eclipse - unable to create build def property types resource and translator (214219). This should be fixed in 4.0.0.1.
Robin