ETL job executions take longer time than expected
The ETL jobs used to take 5-6 hours earlier, then it has reached to almost a day and now its running for almost 2 days (1 day 23 hours).
ie; We do not see any failure of the jobs, but the time taken alone is longer than expected.
Any inputs ??
Thanks
One answer
As I recall 4.0.1 was rather 'piggy' in this regard, we've since upgraded on odd intervals ( 4.0.3, 4.0.5, and now 4.0.7)
Comments
Thanks Kevin
We are using RRDI for RQM. and this setup is configured only for RQM/RRC.
We are using RRDI for RQM. and this setup is configured only for RQM/RRC. We have all the JTS, RQM and RRDI on the same server only. They are under the same roof. However, on reading the logs for db2 instance I see the below
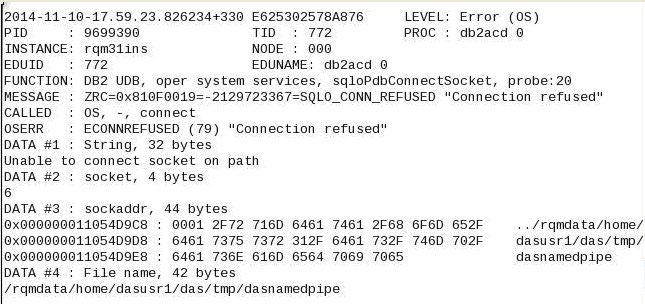
That's the db2 admin instance ( dasusr1 ) and a connection refused would, in my experience, prevent something from working altogether, not just make it slower. Have you watched: aix topas, iostat, vmstat or db2's db2top ?
In topas look for large percentage of Wait time. iostat will show disk activity ( e.g. iostat 4 to collect and display each 4sec ). Those measurements will guage the overall performance of your server. DB2 db2top can show what's currently going on, e.g. Lock wait applications, active tablespaces,tables, etc.