Caching server useful for RTC workitems ?
4 answers
yes the original public uri is to the IHS server, but the IP address will be to the nearest proxy, regardless of where you are.
we are a global company, and people travel to other locations for meetings and work sessions, taking their laptops with them. When they are in a different location they should not have to change their configuration, even tho the IP address of the closest proxy is different.
the 'easiest' way to implement a transparent proxy is to just change the DNS server to map the same name to the proxy instead of the IHS server. poof everyone is now talking to the proxy (in our HQ location).
but the data traffic still travels across the WAN to most of our users. so we need a second proxy in each office location. (mostly where software builds are done as well). so how to intercept the resolved HQ proxy address in the remote offices and redirect it to the office resident proxy.., we use WCCP for that.
the DNS resolved IP address for the public uri in the remote office is the same as it is in HQ (proxy2), but the routers use WCCP to detect that and change it to the local proxy address. (if the local proxy were to fail, rather than have the request fail, it will flow to the HQ proxy, just won't be as fast)
so the users use the public uri of the RTC (IHS) server, and the DNS servers and routers change the underlying IP depending on physical location. In the austin office it will be to the local office location proxy. in the california office the same, and if someone travels to our headquarters location, the same.
the proxies are configured to the an alternate dns name for the cache peer stmt
so the rtc user in austin talks to proxy1, and proxy1 talks to proxy2 in HQ, and proxy2 talks to IHS which talks to websphere.
the rtc user in california talks to proxy9, proxy9 talks to proxy2 in HQ, etc..
if either user is in the HQ location, their RTC usages talks to proxy2 without their knowledge.. (DNS resolution).
proxy2's job is to keep repetitive extracts from impacting the RTC server instance.
proxy1 (and proxy9)'s job is to provide as close to local lan speeds for users as possible (and to keep repetitive traffic off the WAN altogether)
pre-proxy:
rtc1.server.domain = 192.168.1.100
post proxy :
rtc1.server.domain = (HQ) 192.168.1.200, (Austin) 192.168.2.200, (california) 192.168.3.200, etc.
austin & california proxy servers have cachepeer = rtc1.proxy.server.domain (192.168.1.200)
HQ proxy (rtc1.proxy.server.domain) has cachepeer = rtc1.server.direct.domain (192.168.1.100)
the user still uses rtc1.server.domain in the web UI, the eclipse and build configs.
the traffic just goes somewhere else.
the DNS servers still return ONE IP address. rtc1.server.domain = 192.168.1.100 (old), 192.168.1.200 (new)
and the remote routers intercept and and change it to the local address.
so overnight everyone will start using the proxies without knowing.
so all the source code, javascript, and static web text (headings, etc) get pulled to a lan speed server as close to the consumer as possible. We don't send repetitive stuff over the WAN more than once (and the WAN accelerators on the wire reduce duplicate bit patterns 40-95%), we also don't extract if from the RTC database more than once.
the main office proxies are in place, and the remote office proxy machines are in transit to the high traffic offices as we speak.
everything inside the blue circle is inside our HQ location where RTC is located
note: before the jumpstart team wants to choke me!, this is an extreme solution, for our environment, you could get 90% of the server benefit with just proxies at the HQ location.
and 90% of the speed benefit with proxies just at the remote locations( but we need a proxy at the HQ location anyhow as if it was a remote location), so we might as well piggyback and get the best of both.
this tiered proxy architecture has been used on the web forever, so this is not invention.
before proxies

with proxies
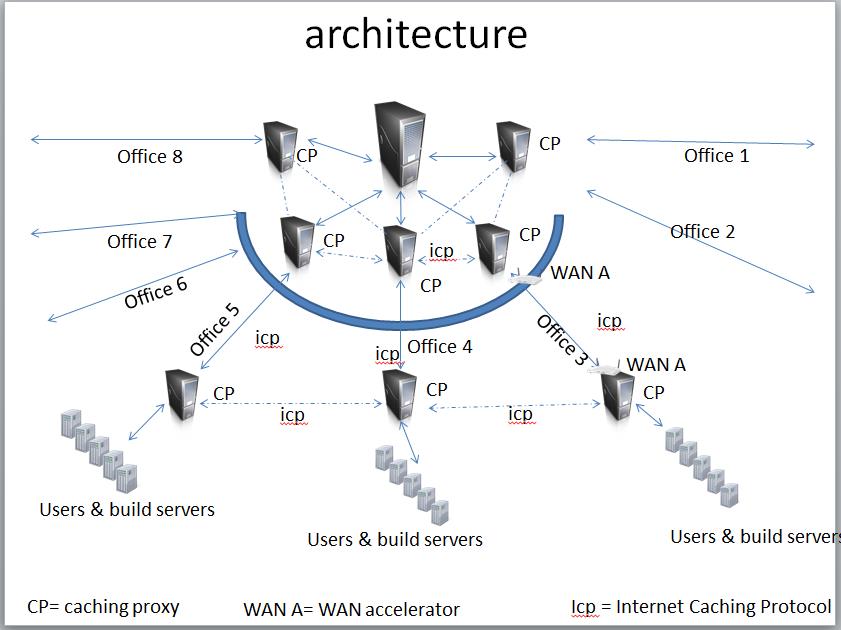
we have 5 RTC servers(for capacity), so right now we have 5 master proxies in the HQ location, 1 for each. when we decided on our public URI on RTC 2, we didn't anticipate the proxies, so its hard to use one proxy for multiple servers.. this is one thing we hope we can resolve with server rename after we upgrade from 3.0.1.1 to 4.x later this year. (I want multiple load balanced identical proxy servers, with ICP to keep them in synch, then we don't run the risk of overloading one proxies cpu capacity)
(and if there was project move support, we think we could consolidate the RTC servers to a single instance, with clustering for failover, after removing the redundant file extracts and the wasted RSS feed demand (enhancement in 4.0.3), which account for >80% of the cpu load on server and DB)
Comments
Hi Sam, great article. May I ask some stuff?
- rtc1.server.domain = 192.168.1.100 : is this correct below you write
rtc1.server.domain = (HQ) 192.167.1.200 and a bit later:
rtc1.server.direct.domain (192.168.1.100) and then
rtc.server.domain = 192.168.1.100 (old), 192.168.1.200 (new)
Oh, and some more questions:
sorry on the typos, corrected above.
yes using squid.
as for ICP between, as you can see our network is hub and spoke, but there are a few cases where the people at multiple locations are working on the same product. so having a network that allows sharing directly also helps. We've tested this and it does what we want.. if we need it to reduce the bandwidth consumption on the hub/spoke links. (the picture is architecture!)
we use two different WAN routers, Riverbed and Cisco. they both provide on wire acceleration.. Cisco's is called WAAS. Net, they detect repeating bit patterns and replace with a token that the other end knows about and restores the bit pattern on the output side.. for source code this was like 95% reduction of bits moved across the wire (for 2nd thru nth iteration). For HTTPS applications, you must import the certificates into both router ends, so that the routers can see inside the data stream. its only for the specific application (RTC) so no privacy concerns for email over the same link.
the second function is the WCCP interception in the remote offices. the two functions are unaware of each other.
an example of where the WAAS works is if you change one line of code in a source file, RTC will send a new artifact (Dan said 'gets a different URI handle') to anyone asking for that file. so it will flow to the caching proxies and across the wire.. but maybe 100 chars changed of a 2k file.
the WAAS function will reduce the actual wire transfer bits to less than 200 chars, and the remote proxy will still get the 2k file.
why go thru this work? 1 its easy, 2 RTC web is a chatty application, making lots of rest based api calls for each (planning) page. so wan bandwidth is a precious commodity. here the WAAS function also helps. workitem data is pretty stable.
this doesn't help response time much, but it provides wan capacity, so the operations become more consistent.
Luckily the router cpu and storage are faster than the wire transfer speed
Comments
Hi Daniel,
I recently received a request from a customer asking about using IHS for caching content. I also learned from my colleague that one of his customers is also looking to deploy caching proxy for performance improvement for work item and plan.
Questions:
1. In the case when the server is not used for SCM, but more on work item and plan, would there be any negative impact to the performance if the caching proxy is deployed?
2. Do you know if we have any plan to support caching proxy server other than SQUID? (there is an RFE ==> http://www.ibm.com/developerworks/rfe/execute?use_case=viewRfe&CR_ID=34394
and related question ==> https://jazz.net/forum/questions/85231/supported-caching-proxy-server)
For Workitem caching we deploy WAN accelerators into the remote locations. SQUID is not helping at all for this, we tested this.
We see network traffic optimization up to 85% with the RTC WEB UI (https) by using WAN accelerators. Average is more than 50%. And very important is also the latency is significant reduced and also stable if the network capacity is is highly used..
Another Problem with the reverse Proxy like SQUID is the need of the stable URI. This URI is pointing to the central Server and not to each reverse Proxy in the world. You would need a DNS entry which is Client subnet depending, so the traffic is realy routed through the reverse proxy. This can only be done with BIND, but not MS-DNS. Maintain local hosts file is also not working with java based software, because the ipname resolution order is not going through the hosts file, if the entry exists in DNS.
Add-on:
If CLM is not used for source code management, but for requirements/planning/tracking/testing etc. an alternative solution we also have in place is terminalservices. We have one central TS beside the CLM webserver. On them we have Firefox ESR and RTC-Eclipse published. With the receiver software on the Client, users have this two applications available as Icons on the Desktop. So they have the best Performance you can get.
Comments
We have a two tiered cache structure. all the clients talk to one of the cache servers. (the public uri of the RTC servers is also dns mapped to the proxy) The routers in the remote offices use WCCP to redirect the clients to the nearest cache.
if the user travels to the home office (where the 1st tier is setup), the dns server routes the same name to the cache server.
Of course we also have the IHS reverse proxy in front of Websphere so that we can move the logical servers around while keeping the same url.
we also use WAN accelerators on our wan links that reduce the wire consumption by ~90% leaving bandwidth for other applications. We extract a LOT of source code every day.
Sam, I would like to learn more about your DNS/router name resolution. It sounds like you have a solution for this single public URI issue, where i'm stucked in. The key seems to be the WCCP protocoll.
Question to better understand:
- You write "the public uri of the RTC Servers is also dns mapped to the Proxy.". You mean the IHS Proxy in front of WAS? So you have also only ONE ip address for the public URI in global DNS? And this one is in the router of the remote location redirected to their cache server?
- The second statement with the home office I do not understand exactly.
- Do you have a drawing about this?
We're looking at trying to implement something simple using Websphere Caching Proxy, so this is great.
In return for not choking you, would you consider writing this up for the Deployment Wiki?
Freddy
Comments
deployment wiki?
Hi Sam, that's a fantastic writeup. Here is the Deployment Wiki and this is pretty new. Freddy might tell you more about it.
Comments
sam detweiler
May 17 '13, 6:14 p.m.we see a small gain for web based content, mostly Plan views, which load a lot of javascript and gui elements.
Doesn't help eclipse at all for non-SCM data.