Implementing Jazz application HA using PowerHA
Authors: TimFeeney, RickRakichBuild basis: Jazz products in CLM and SSE
The IBM PowerHA SystemMirror software provides a low-cost commercial computing environment that ensures quick recovery of mission-critical applications from hardware and software failures. This high availability system combines custom software with industry-standard hardware to minimize downtime by quickly restoring services when a system, component, or application fails. Although not instantaneous, the restoration of service is rapid, usually within 30 to 300 seconds.
PowerHA is designed to ensure application availability in the event of system failures, operator error or planned maintenance. Servers or LPARs are grouped into clusters that monitor each other; if a failure makes an application unavailable, it can be restarted on the backup hardware. Administrators can also deliberately move/activate an application on backup hardware in order to perform maintenance without affecting the application.
Clustering two or more servers to back up critical applications is a cost-effective high availability option. Application clusters also provide a gradual, scalable growth path. It is easy to add a processor to the cluster to share the growing workload. You can also upgrade one or more of the processors in the cluster to a more powerful model. If you were using a fault tolerant strategy, you must add two processors, one as a redundant backup that does no processing during normal operations.

A typical two node cluster
PowerHA uses a heartbeat mechanism sent between nodes and to a shared disk to detect and diagnose failures.
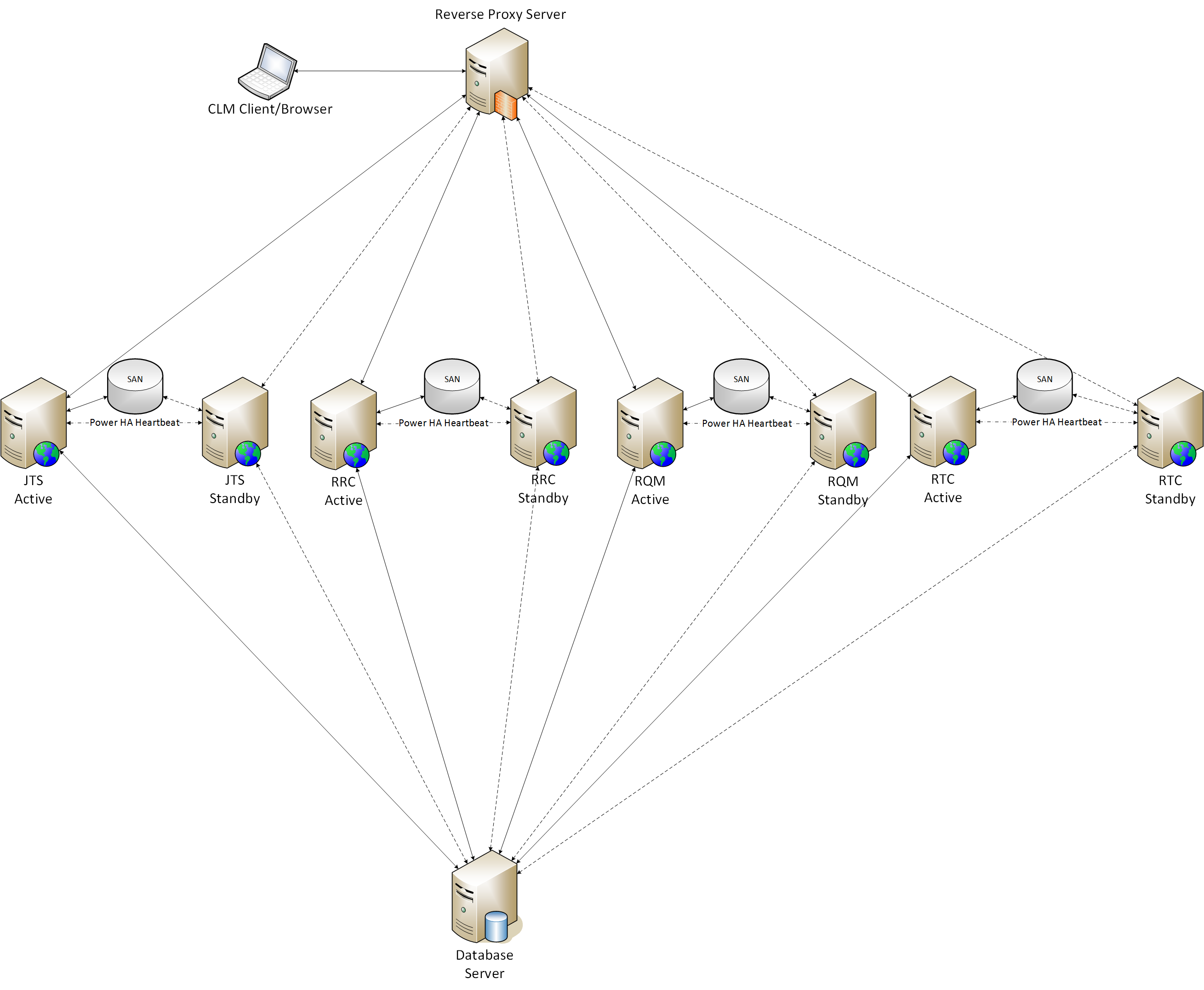
Recommended CLM PowerHA topology
In this distributed enterprise topology, based off of the CLM-E1 topology, each Jazz application runs on its own primary LPAR and has a secondary/standby LPAR with the same configuration (memory, CPUs, etc.). The secondary LPAR has at least the OS running and possibly WAS but not the secondary application instance.
Jazz application recovery
PowerHA can further monitor applications in one of two ways:
- Process Monitor – determines the death of a process
- Custom Monitor – monitors health of the application using a monitor method you provide
Decisions upon failure
- Restart – Can establish a number of restarts to restart locally. After a specified restart count, if app continues to fail you can escalate to a fallover.
- Notify – Send email notification
- Fallover – Move application and associated resource group to next candidate node.
Application Monitoring can be suspended/resumed at anytime.
A simple script using curl can be written to detect whether a Jazz application is available or not. For example,
curl -s -o /dev/null -w "%{http_code}" http://www.example.org/
will return an HTTP code of 200 if the application at www.example.org is accessible. A script using that statement and some additional code could be written that looks for anything other than 200 or specific error codes and counts these occurrences to determine if the application is inaccessible. This could then be reported to PowerHA and a recovery process activated.
Configure PowerHA recovery process to restart the failed Jazz application. If the application fails to restart after 2-3 times, restart WAS per WasRecovery. A simpler approach would be to avoid the restarts and failover to the secondary LPAR.
WAS recovery
Configure PowerHA Smart Assist for WebSphere to detect if WAS is available. If not, use the start/stop scripts provided by the Smart Assist to restart WAS up to two times and then the Jazz application. If WAS does not restart successfully, PowerHA fails over to the secondary LPAR.
Single LPAR recovery
If PowerHA detects the loss of heartbeat packets failover occurs.
- Shutdown the primary instance of the application
- Transfer the SAN data partition with the Jazz indexes from the primary to secondary LPAR
- On the DNS server, transfer the hostname resolution of the secondary LPAR (i.e. update the routing so the public URI resolves to the secondary LPAR)
- Start-up the Jazz application on the secondary LPAR
- Secondary LPAR has OS and WAS running
Other considerations
It is imperative that the configuration of the secondary application nodes be kept in sync with their primary. Any software upgrades, hotfixes, application configuration chages, etc., made on the primary node need to be applied as well to the secondary. Otherwise, you run the risk that the failover will fail or not provide the same level of service.
Benefits of a PowerHA based Application HA solution
This solution is very similar to a cold standby solution. The key difference is the automation provided by PowerHA. You could have a phased implementation that starts with a manual cold standby configuration and progressively evolves to a fully automated configuration.
PowerHA is a mature Power technology and is already in use at many enterprise customers for their application, data and storage tiers.
- Offers automated failover with faster recovery time leading to more reliable, less error prone failover
- Greater confidence in failover improves triaging options of SW or HW issues in production by using failover to secondary
- Can be extended to support availability in the web tier (redundancy of the reverse proxy servers)
- Has capabilities to support Disaster Recovery as well
The two node configuration described above is a very common configuration, relatively fast to implement, low complexity and low risk.
Related topics: Approaches to implementing high availability and disaster recovery for Rational Jazz environments, High availability principles
External links:
- PowerHA SystemMirror 7.1 for AIX PDFs
- PowerHA SystemMirror concepts
- Smart Assist for WebSphere
- Introduction to PowerHA
Additional contributors: None
-
 Deployment web
Deployment web
-
 Planning and design
Planning and design
- Installing and upgrading
- Migrating and evolving
- Integrating
- Administering
- Monitoring
- Troubleshooting
Status icon key:
-
 To do
To do
-
 Under construction
Under construction
-
 New
New
-
 Updated
Updated
-
 Constant change
Constant change
- None - stable page
- Smaller versions of status icons for inline text:
-





Contributions are governed by our Terms of Use. Please read the following disclaimer.
Dashboards and work items are no longer publicly available, so some links may be invalid. We now provide similar information through other means. Learn more here.