High availability principles 
Authors: GrantCovell, StevenBeard, StephaneLeroy, ScottRich Build basis: None
High availability (HA) and disaster recovery (DR) are both related aspects of Wikipedia: Business continuity planning.
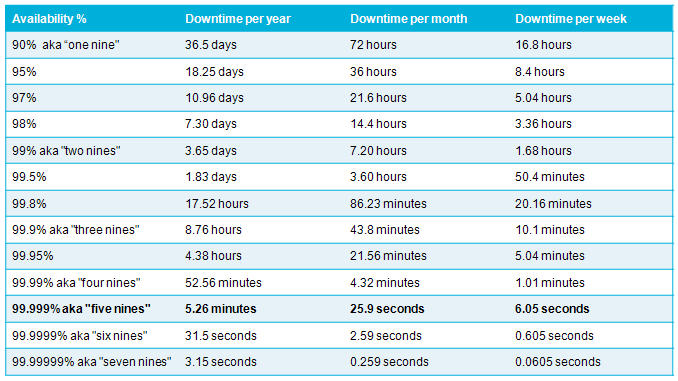
Percentage availability table
Availability is a measure of the time that a server or process functions normally for general usage, as well as a measure of the amount of time that the recovery process requires after a component failure.
High availability is system design and implementation that achieves system and data availability almost all of the time, 24 hours a day, 7 days a week, and 365 days a year. High availability does not equate to 100% availability. To achieve 100% availability is not a cost-effective reality for the large majority of implementations today; rather, it is a goal - IBM High Availability Solution for IBM FileNet P8 Systems.
High availability is a system design approach and associated service implementation that ensures a prearranged level of operational performance will be met during a contractual measurement period - Wikipedia: High availability.As Rational development environments become larger and support larger user communities, HA of these environments is becoming increasingly essential within most organizations. Development is increasingly considered a core business function by many organizations and as such poor availability of the Rational development environment used to support it can have large business cost and capability implications. The related Disaster Recovery topic focuses upon a major failure of the primary data center requiring failover to a secondary disaster recover data center or fundamental rebuild of the primary data center. This topic outlines the different principles of HA that you should consider when designing a Rational development environment. It is critical that HA is considered from the outset of designing your environment because the design itself will constrain the HA solution. HA that is developed as an afterthought may result in significant rework of the environment or result in a suboptimal solution. However, the first thing to consider is what are your organizations real requirements for HA based on your business and technical needs and requirements for the environment itself.
Availability - "number of nines"
Availability is usually expressed as a percentage of up-time. The notion of "number of nines" relates to increasingly higher levels of availability, where a greater number of nines signifies a greater percentage of HA or up-time. For example, "Five nines" equates to an up-time of 99.999%. The following table shows the downtime per year, month and week allowed for a particular percentage availability assuming that the environment is required 24x7x365(6) days a year.Percentage availability table
Measuring availability
Availability is measured in percentage of time. If an environment is available 99% of the time for normal business operation, the environments availability is 99%. This availability percentage translates to the average of the specific amount of downtime per day, per month or per year. To truly measure the availability of an environment, we must first differentiate the planned outages and the unplanned outages. Planned outages take place when the operations staff takes a server offline to perform backups, upgrades, maintenance, and other scheduled events. Unplanned outages occur due to unforeseen events, such as power loss, a hardware or software failure, user operator errors, security breaches, or natural disasters. Availability is usually only measure for supported business operating hours for an environment. Some organizations only support Rational development environments for core business hours, such as 08:00 - 19:00 Monday to Friday. Increasingly due to geographically distributed development and development outside of core business hours, environments are often supported for extended hours, sometimes approaching 24x7x365(6). However, it is always good practice to have regular scheduled outage windows for back-up and maintenance. Further, it is critical that administrative staff for all tiers of the Rational development environment are available on site or on call for supported hours to ensure that any HA/DR solutions perform correctly and to support unforeseen failures! It is important that you establish a way to measuring your environments availability to be able to assess whether you are meeting or exceeding your required availability.Mean Time to Recovery (MTTR)
MTTR is the average time that an environment will take to recover from all or specific failure scenarios. Sometimes an organization will focus on only HA scenarios within the primary data center and exclude DR scenarios.Related topics: Disaster recovery, Approaches to implementing high availability and disaster recovery for Rational Jazz environments
External links:
- IBM High Availability Solution for IBM FileNet P8 Systems - some of the descriptions on this page are strongly derived from this IBM Redbook.
- Deploying Rational Team Concert on WebSphere Application Server for high availability using idle standby
- Availability concepts
Additional contributors: HariVetsa, MattLavin
Contributions are governed by our Terms of Use. Please read the following disclaimer.
Dashboards and work items are no longer publicly available, so some links may be invalid. We now provide similar information through other means. Learn more here.