Burnup and burndown - are they really correct?
Hi RTC experts,
we are currently experiencing acceptance problems of the IBM Jazz RTC because our teams are questioning the burnup and burndown charts. They believe the lines in the charts are incorrect.
The following situation is causing these issues: Imagine the iteration contained 10 stories. 9 of them are done and one is not. The total estimation for the open stories’ tasks is 200 hours. One task of 10 hours is still open. The sprint ends. In the next iteration we will finish this story so we move the task (= 10 hours) to the next iteration.
Due to the fact that all lines on the burnup chart start at 0 they also expect the "Work done" to start at 0. What we see is that the "Work done" starts at 190. This is theoretically correct if the burnup chart (same applies to the burndown chart) takes the underlying user story as basis.
When they start planning an iteration and take this data into consideration then someone in the team needs to be aware that the total capacity of the team is NOT 510 as indicated in the chart, but it is 510 + 190. The same applies to all of the other lines. We believe that the all lines ("Planned work", "Linear complete", "Expected complete", "Capacity burnup", "Total capcity") should be raised by 190. Everything else is misleading.
How do you see this?
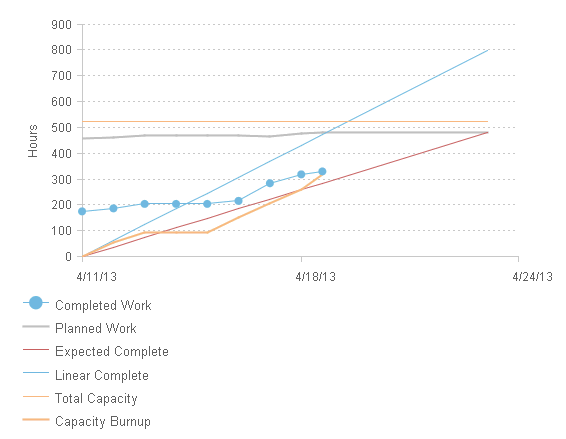
We have switched to burnup chart because the burndown chart does not provide the information we need to manage a team. The ideal line contains the weekends (this should be resolved with 4.0.3) and the "Expected complete" is just a line that connects the last "Work Done" point with the 0 at the end of the sprint. From our point of view the burndown chart just provides an overview of "Planned work" and "Remaining work". We want to answer the question "Will we be able to finish this sprint or not" cannot be answered using this chart.
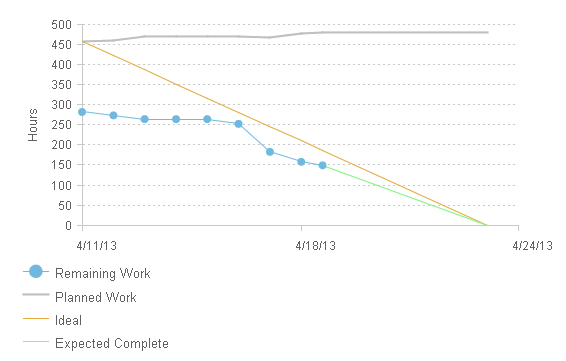
How do you answer these questions based on these charts?
It would be great if you could give me some hints on that.
Michael
2 answers
My opinion (but im not IBM developer)
- If the story is planned for the past sprint, there is absolutly no reason to add the hours of the resolved tasks of a past sprint as completed work to the current sprint.
- But regardless of this if the resolved tasks are planned for the past Iteration, the hours should never be added as completed work in current sprint. That's just wrong. Not in the Burnup nor in burndown.
- I cannot understand how the report is able to take this tasks, because you wrote that the Story is planned for the past sprint and also the resolved tasks are planned for the past sprint. So only the hours of the open task which is planned for the current sprint should be added to remaining work of current sprint.
- Maybe you can post a Screenshot of the progress and load bars, of the header of the Sprint plan. The values there must correspond to the graph. If not this would be another indicator of a bug.
Conclusion:
- if the szenario is realy like you describe, the completed work at sprint start must be zero.
- I think you should file a defect. Maybe you can post here the defect ID. I'm interest to track this, because we have similar szenarios in our company. (I will now go through our charts. This issue never came up until yet here)
Remarks:
- I would always move also the Story into the current sprint. I do NOT allow any open work in past sprints. It makes house keeping much easier this way. Beginning of each sprint all progress bars of past sprints should have 100% completted (green).
- To estimate if we can complette the sprint successfully, we are using the Progress and Load bars in the header of the Sprint Plan. Unfortunatly, the burndown graph is wrong there in 4.0.1 (should be fixed in 4.0.2).
- The fact that the Burndown is not showing the capacity should be reported. The Burndown should show the sme details like the burnup.
- You write "The ideal line contains the weekends (this should be resolved with 4.0.3)" . What is the change in V.4.0.3? How can this be changed? Weekends are an individual setting of a Contributor and not a Team Setting. So there maybe people working on Weekend and others not.
Comments
Guido Schneider
Apr 26 '13, 9:37 a.m.I like your question.
Just before I answer a clarification question:
- the open Story you have also moved into the new Iteration together with the open task?
- the already resolved tasks stay in the Iteration where they were completed?
Michael A.
Apr 26 '13, 9:55 a.m.Hi Guido,
thank's for your fast response.
The story is not moved to the iteration, in most cases we just assign the new "Planned For" to the task.
Yes, the resolved tasks stay in the iteration where they were completed.
Regards
Michael
Rafik Jaouani
JAZZ DEVELOPER Apr 29 '13, 5:59 p.m.Hi Michael, when you display data about a particular sprint, you need to only select that sprint in the iteration parameter. Make sure you also deselect the the "current iteration" check box. I think the problem I am seeing is that you are starting a sprint where some work items already have the value of time spent not zero. I would suggest you do not carry over work items between sprints. If a work item is not done and you need to carry over the work to the next sprint do one of the following:
1) close the work item and create a new one.
or
2) reset its time spent value to zero and reduce its estimate by the time already spent.
I prefer 1) since it is not going to affect the chart of the previous sprint.
Michael A.
Apr 30 '13, 3:10 p.m.Hi Rafik,
Guido Schneider
May 02 '13, 8:34 a.m.I complettly agree. Both variants are not acceptable.
We move open tasks and open Stories into new sprints to complete them. Resolved Tasks remain in the Sprint where they were solved. We do not allow open work (Story or tasks) in past sprints.
The hours from such moved tasks must be added to the Burnup. If already spent then to the Completed Work at the beginning. The effective estimation must be added to the planned work from beginning.
If I understand Michael, he sees hours from tasks which do NOT belong to the selected iteration.
Rafik Jaouani
JAZZ DEVELOPER May 03 '13, 5:18 p.m.Hi Michael,
The first point of a sprint will never be zero because remember data gets collected at the end of the day and work could have been done during the first day of the sprint. So it is going to be hard to know if that work was done during that day or was carry over from a previous sprint or both. Unless we fetch the history of each individual work item and try to analyze when the work was done and when the work items were re-targeted from one sprint to the other.
Currently the report does not fetch individual work item. Doing so will make the report extremely slow.
We could blindly make an assumption that the first point is carry over work and do as you suggest. But would that be acceptable?