Reusing DD names in sequenced translators
2 answers
the DD Names List utilizes the DD Name substitution facility that the IBM compilers, assembler and DFSMS utilities use. You can find information relating to this in all of the programming guides and utility reference. But for ease of reference I provided this in an SCLM redbook in Appendix E - DDname substitution lists. So to answer your 2nd question, "would this work in other cases where we use our own DD Card names" the answer would be no. However there is an option that may work for that, I will come to that in a moment. So to answer your first question, "Does this mean that I have to specify a different name for SYSUT2 in the DD Names list?" the answer is yes. A good example is IEBGENER. I uses SYSUT1 and SYSUT2 for input and output. If the output from SYSUT2 needs to go into the COBOL compiler then there will be an issue, as COBOL also uses SYSUT2, but for a work data set. So to get this to work the IEBGENER step needs to use the DDname list, and specify Keep on the temporary data set.
The data set definition for the temporary data set defines a data set name of &&TEMPSRC.
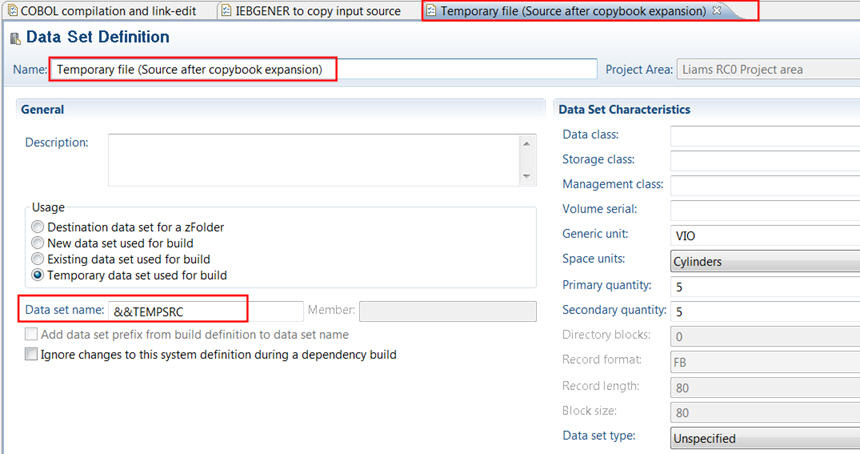
Then language definition in the example I will use has a 1st translator of IEBGENER that will copy the actual source into a temporary data set. The 2nd translator is the COBOL compile that will take the temporary data set as input.
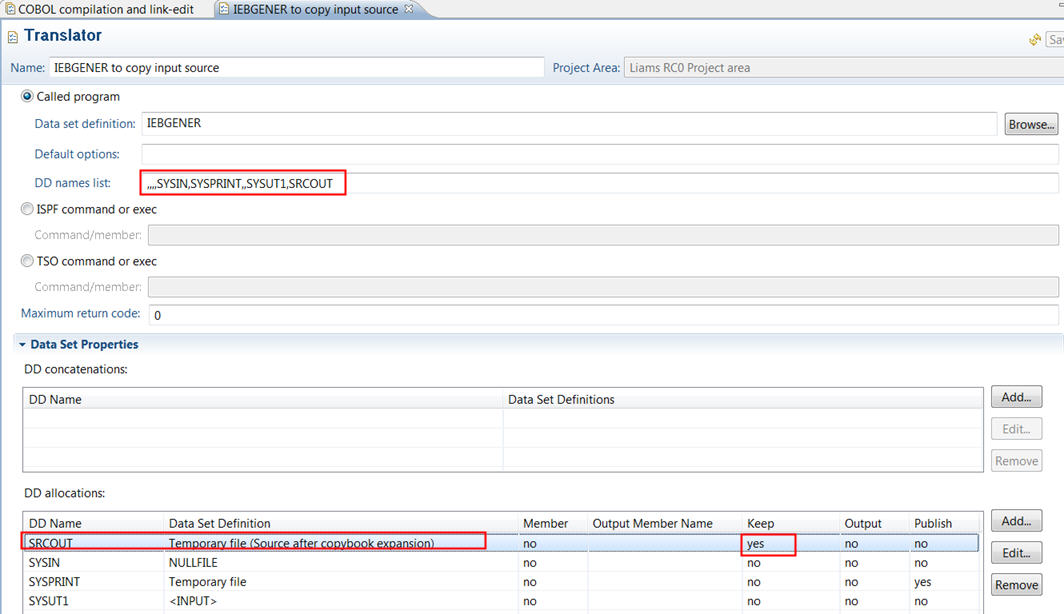
For the IEBGENER translator the DDnames list has ,,,,SYSIN,SYSPRINT,,SYSUT1,SRCOUT so we are replacing SYSUT2 with SRCOUT. Note the 4 "," at the beginning as the ddname substitution is positional. Then in the DD allocations we allocate DD SRCOUT instead of SYSUT2, and use the data set definition that defines &&TEMPSRC using the KEEP option.
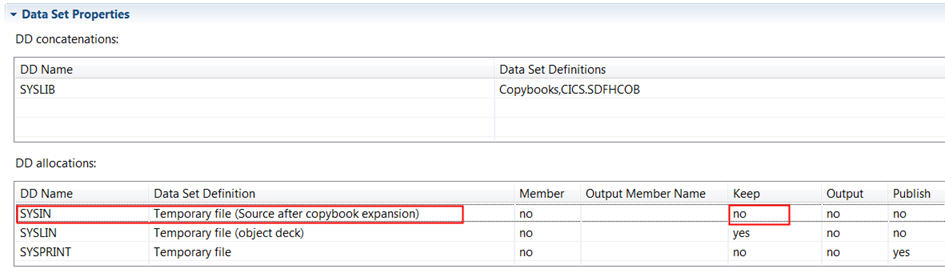
Finally in the COBOL compile translator we use the definition that defines &&TEMPSRC and associate that with the SYSIN DD. This will allow the compile to work as SYSUT2 can be allocated normally by the COBOL compile step.
We can use IEBGENER steps in a number of translators including your own home written ones. If there is a conflict in DD names between 2 translators you can always put an IEBGENER in between them to rename the data set names as IEBGENER supports the DD names list.
Comments
Hey Liam, thanks for the response.
BTW, where do we stand on conditional translator support? I saw that there was some support planned for 5.0.1 but it seemed that some of the work was decommitted from reviewing the work item but I'm not sure exactly what made it in and what didn't. We'd like to use the source expansion step as a means of figuring out if we need to invoke the CICS or DB2 preprocessing steps prior to running the compile step (rather than using the co-processor feature) since we don't know if the code will remain consistent with the language definition we associated with it at zimport time (i.e. it could have had CICS/DB2 processing at import time but perhaps this was removed later on which could invalidate the associated language definition). We'd rather compute what preprocessing needs to happen based on the analysis we do during our source expander at build time.
While I have your attention, we ran into a strange situation when we tried to fix our source expander to allow overriding what DD card to use (instead of SYSUT2). We added a new (Dev) loadmod into the front of the TASKLIB to run a new version of the source expander that supported this new capability. Unfortunately, the build stopped at the call to the source expander. Our theory is that the Dev loadmod was in a PDSE whereas the rest of the entries in the TASKLIB were in PDSs. Is mixing data set types a limitation?
For the 2nd, looks like you found what you needed.
For the 3rd, not a limitation that I am aware of. I just checked my COBOL/CICS/DB2 co-processor translator and I have a mixture:

Were all your blocksizes the same? Not sure that would make a difference. Did all the libraries in TASKLIB need to be APF authed, and the one you added was not? I would expect to see a S047 abend in the system log if that was the case.