r2 - 2018-02-01 - 20:23:05 - Main.ndjcYou are here: TWiki >  LinkedData Web > RwattsSandbox > BestPractices > WritingSPARQLQueriesThatCompensateForAlternateTypesOfStringLiterals
LinkedData Web > RwattsSandbox > BestPractices > WritingSPARQLQueriesThatCompensateForAlternateTypesOfStringLiterals
| This wiki: The development wiki is a work area where Jazz development teams plan and discuss technical designs and operations for the projects at Jazz.net. Work items often link to documents here. You are welcome to browse, follow along, and participate. Participation is what Jazz.net is all about! But please keep in mind that information here is "as is", unsupported, and may be outdated or inaccurate. For information on released products, consult IBM Knowledge Center, support tech notes, and the Jazz.net library. See also the Jazz.net Terms of Use. Any documentation or reference material found in this wiki is not official product documentation, but it is primarily for the use of the development teams. For your end use, you should consult official product documentation (infocenters), IBM.com support artifacts (tech notes), and the jazz.net library as officially "stamped" resources. |
Best Practice: Writing SPARQL Queries that Compensate for Alternate Types of String Literals
State: Approved Contact: Nick CrossleyScope
In RDF 1.0 there were three alternative ways that a literal value can be encoded. A literal could be either plain or typed. Furthermore, a plain literal could have an optional language tag. These alternative values were distinct. In RDF 1.1, which we use in CLM products today, this was simplified. A plain literal was defined to be of type xsd:string, and a plain literal with a language tag was defined to be of type rdf:langString, so all literals are typed. For typed or tagged values to be equal, their types or tags must also be equal. These differences might result in unexpected query results unless you take care in writing the query.Recommendation
The solution is to use the SPARQL STR() function to extract just the string part of the value. SPARQL has other functions for extracting the type and language tag, e.g. if you just want English values.Examples
To illustrate this, consider the following example resource <http://example.com/ex1/> where the string "title" is represented three ways:@prefix dcterms: <http://purl.org/dc/terms/> . @prefix xsd: <http://www.w3.org/2001/XMLSchema#> . @base <http://example.com/ex1/> . <plain> dcterms:title "title" . <typed> dcterms:title "title"^^xsd:string . <english> dcterms:title "title"@en .This example contains 3 triples, as shown by this query:
select *
where {
graph <http://example.com/ex1/> {
?s ?p ?o .
}
}
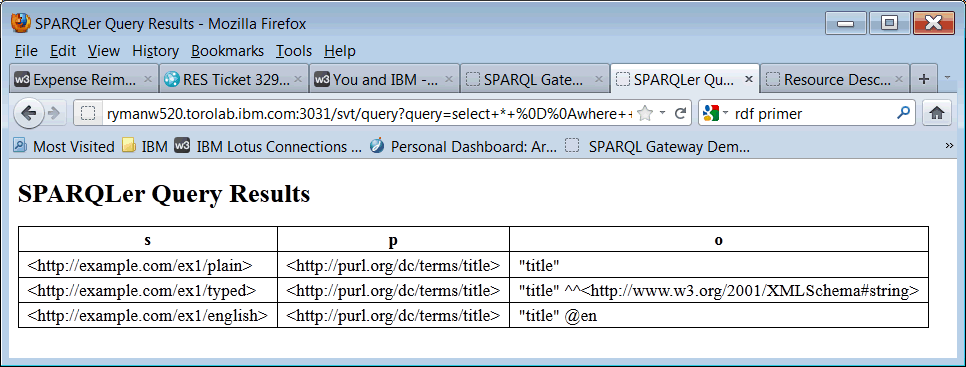 Now suppose we write a query to find all the resources whose dcterms:title is "title":
Now suppose we write a query to find all the resources whose dcterms:title is "title":
select *
where {
graph <http://example.com/ex1/> {
?s ?p "title" .
}
}
The result with RDF 1 would have been just the triple with the plain literal value:
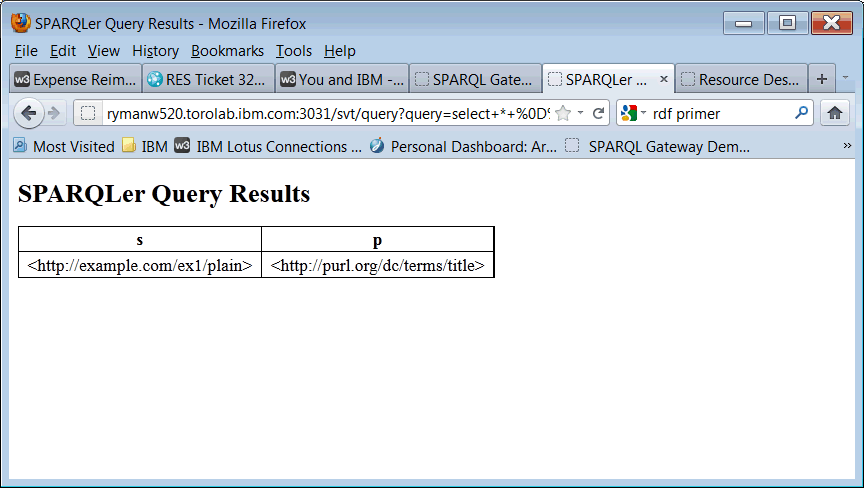 In RDF 1.1, the result includes both the 'plain' literal and the 'typed' literal, because they both have the type xsd:string, as does the literal in the query - so they match:
In RDF 1.1, the result includes both the 'plain' literal and the 'typed' literal, because they both have the type xsd:string, as does the literal in the query - so they match:
 We can use a FILTER clause to get more triples, even with RDF 1:
We can use a FILTER clause to get more triples, even with RDF 1:
select *
where {
graph <http://example.com/ex1/> {
?s ?p ?o .
filter(?o = "title") .
}
}
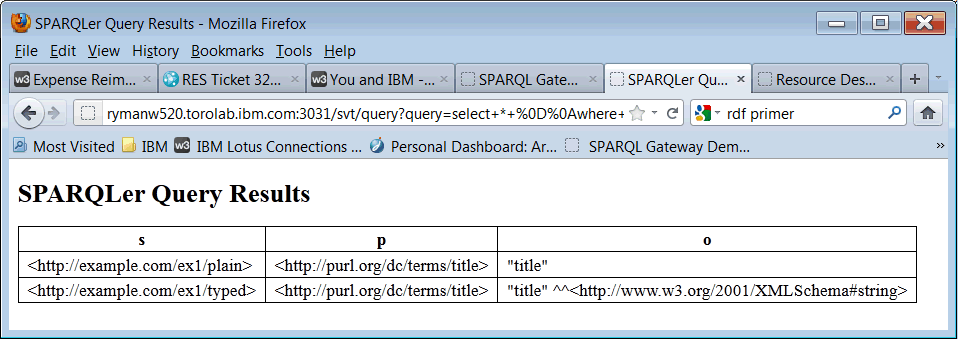 The definition of the SPARQL equals (=) operator does some conversion, but omits the tagged value.
To get all values, use the SPARQL STR function.
The definition of the SPARQL equals (=) operator does some conversion, but omits the tagged value.
To get all values, use the SPARQL STR function.
select *
where {
graph <http://example.com/ex1/> {
?s ?p ?o .
filter(str(?o) = "title") .
}
}



| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
jena3.png | manage | 82.0 K | 2018-02-01 - 20:23 | UnknownUser | |
| |
sparqler1.png | manage | 39.2 K | 2018-02-01 - 17:10 | UnknownUser | |
| |
sparqler2.png | manage | 39.2 K | 2018-02-01 - 17:13 | UnknownUser | |
| |
sparqler3.png | manage | 43.8 K | 2018-02-01 - 17:13 | UnknownUser | |
| |
sparqler4.png | manage | 52.0 K | 2018-02-01 - 17:14 | UnknownUser |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Contributions are governed by our Terms of Use
Ideas, requests, problems regarding TWiki? Send feedback
Dashboards and work items are no longer publicly available, so some links may be invalid. We now provide similar information through other means. Learn more here.