Getting the most out of full text search
Summary
Full text search intelligently searches work items and other artifacts quickly finding close and exact matches in ranked order. The user interface for Quick Search, the primary user interface for full text search, is a simple text box; but to get the most out of search you need know what text to put into it.
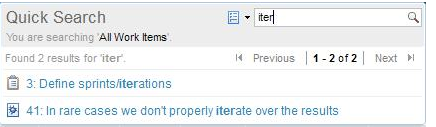
In addition to Quick Search, you can use the query editor to create a full text query. The full text part of the search is one condition in a larger query.
You can use full text search to find a single word, part of a word (via a wildcard search ‘*’, ‘?’), or multiple words, in exact order, or in any order, including some missing words. For example, to find all work items that contain the phrase change request enter "change request". To find all work items containing change, or containing request enter change request without quotes.
Client side full text search is available via , allowing you to quickly find recently used work items, plans, and other artifacts.
Background
First, here’s some background on how text search works in general. Unlike most RTC operations, full text search doesn’t query against the database, instead it searches a Lucene index built by RTC stored on the server. Lucene is an open source search technology (see Lucene: Ultra-fast Search for more details).
The Lucene Index is built dynamically as you interact with RTC. For example, when you create a Work Item, the Work Item is also indexed. A frequently run background task updates the Lucene index with new or updated database items.
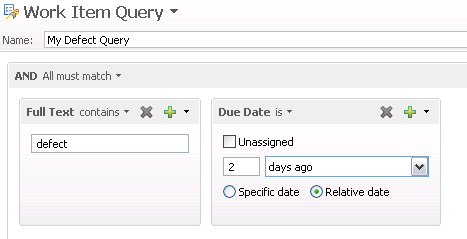
Attribute categorization
The indexing process extracts text from the attributes that make up the work item. Internally each work item attribute is assigned to a category. There are four categories: _name, _content, _tag, and _meta.
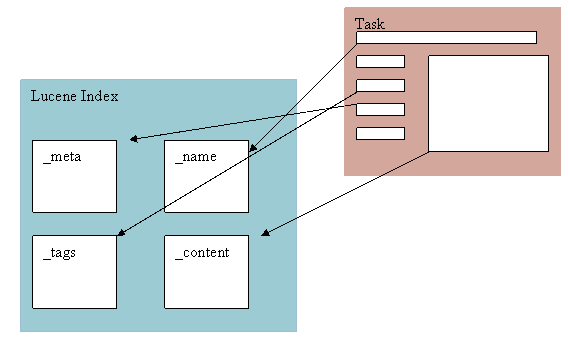
For example, the Summary attribute in a Work Item is categorized as _name, the Tags attribute is categorized as a _tag; the Found In attribute is categorized as _meta.
Below are the attributes and categories that make up a Work Item. All of these attributes contribute text to full text search.
| Category | Attributes |
|---|---|
| _name | Summary |
| _content | Description, Comments |
| _tags | Tags |
| _meta | Target, Approvals, Descriptor, Found In, Owner, Creator, Id |
Tokenizing
Before storing text in the index, RTC first breaks the text down into tokens. The first pass of tokenizing is to break text up the text at white spaces. Each string is considered a token. Text is also broken up at non-letter non-numerical characters (e.g. ‘.’, ‘?’, ‘!’ and /’), capital characters (e.g. CamelCase is broken into Camel Case). All words are converted to lower case.
Common words like “this” or “that” are stripped out. Otherwise, they would cause false matches.
The stemming tokenizer, or stemmer, reduces each token to a root. A stemmer for “iteration” reduces “iteration” to “iter.” The words “iteration”, “iterate”, and “iterates” are all reduced to the same token, “iter.” Later, when a search is run, the search term is also stemmed. Searches for “iteration” will also match “iterate.” They share a common root.
Consider the words “ax”, and “axe”; they share a common stem, “ax.” The word “axis”, has the stem “axi”, and “axiom”, has the stem, “axiom.” The word “real” has the stem “real”, while the words “realize” and “realization” share the stem “realiz.” The stemming algorithm shouldn’t overstem, and find too many matches, nor should it understem, and miss matches.
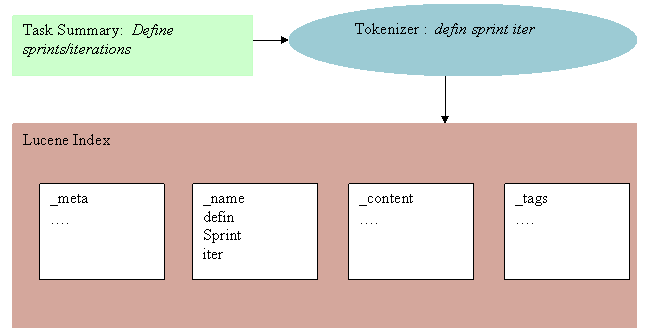
In the Task with a Summary “Define sprints/iterations” is indexed. The summary is stored in the _name category portion of the index. Note that other data such as the character position in the original text and the containing artifact is also stored in the index.
What happens after you press ‘Enter’
Let’s say that you’re looking for the word “iteration” in a Work Item. So you type in “iteration” and select enter. RTC first tokenizes the search string, “iteration.” The same stemming filter is applied to the search string as was applied to the work item text. The token “iter” appears in the query.
The query RTC generates for iteration is
+((_name:iter^2.0 | _content:iter | _tags:iter* | _meta:iter)) +((_artifactType:com.ibm.team.WorkItem.WorkItem _containerType:com.ibm.team.Work Item.Work Item)^0.0)
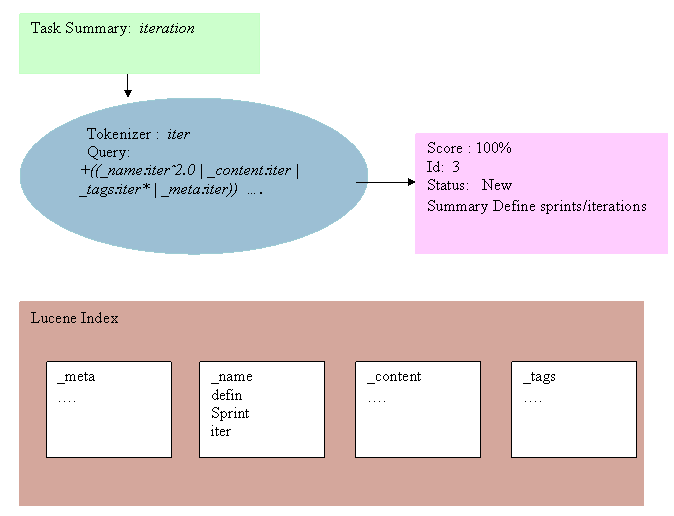
Translated to English the query reads, look for “iter” in any attribute categorized as _name, _content, _tags, or _meta. Consider hits in attributes categorized as _name twice as important as other hits. When looking for “iter” in attributes categorized as _tags, don’t do an ordinary search, look instead for any word that starts with “iter.”
In , only “iter” was typed. It returned a hit on both “iterations”, and “iterate.” But if you type one more letter, “itera”, you won’t get any hits.

The stemmer doesn’t know what to do with “itera”, so it leaves it as it is. The string “itera” doesn’t match anything. To get partial word matches to work, you need to enter “iter*” into the search box. Note that if you enter “iteration” into the tags attributes, then type “itera”, you will get a hit on “itera.” Since the tags attribute is categorized as _tag, the query “itera*” is run against it.
Beyond work items
Note that text in attachments is also indexed. This can produce surprising results if not considered. The attachment file name is also indexed. In addition to work items, plans and source control artifacts can also be searched.
Wildcard search
You can always get around incomplete search results by using wildcard characters (“*” and “?”). The “*” character matches any string. For example, if you entered "i*n", this would match “iteration”, “iterations”, and also “iron.” The “?” character matches any character. For example, "?ace" would match “pace” and “race.” Wildcard searches are slow and best avoided.
Multiword search
Sometimes you need to enter more than one word in the search field. If you put quotes around the text you’re searching on you’ll notice that you get fewer hits. Text with quotes on returns results when all of the words in the text are found, and they are in order. If you just enter text, then not all of the words need to be found and the words don’t have to be in order. The words that are found do need to be near one another.
Here are some details. The first query is run when you just type in text, in this case "define sprint iteration." This query says look for “defin” (tokenized define), in one of the four categories, using the same rules that apply to a single word query. Do the same for sprint, and iteration. See if the results of any of these are within two tokens of one another.
+(((_name:defin^2.0 | _content:defin | _tags:defin* | _meta:defin) (_name:sprint^2.0 | _content:sprint | _tags:sprint* | _meta:sprint) (_name:iter^2.0 | _content:iter | _tags:iter* | _meta:iter))~2) +((_artifactType:com.ibm.team.WorkItem.WorkItem _containerType:com.ibm.team.Work Item.Work Item)^0.0)
If you enter define sprint iteration without quotes a different query is run.
+(spanNear([_name:defin, _name:sprint, _name:iter], 0, true)^2.0 | spanNear([_content:defin, _content:sprint, _content:iter], 0, true) | spanNear([_meta:defin, _meta:sprint, _meta:iter], 0, true) | spanNear([_tags:defin, _tags:sprint, _tags:iter], 0, true)) +((_artifactType:com.ibm.team.Work Item.Work Item _containerType:com.ibm.team.Work Item.Work Item)^0.0)
In this case the query says that in the one of the categories of the Work Item index, the tokens “defin”, “sprint”, and “iter” must appear in order.
Client side index
In addition to the Lucene index on the server, there is also an index that keeps track of artifacts that you’ve visited in the past with your Eclipse Client . The client side indexing also uses Lucene, but maintains the index on the client machine. The index includes work items, queries, plans and wiki pages (names only), attachments (names only).
For more information
About the author
Glenn Bardwell is a member of the Jazz L3 Dev Team. For additional information about the topic presented in the article add your comments or questions directly in the discussion part or visit our Jazz.net Forum.
Copyright © 2012 IBM Corporation