Creating dependencies amongst literals of the “enumeration” type in Rational Team Concert
Summary
This article gives insight on using the Rational Team Concert (RTC) API, for creating dependencies amongst literals of the “enumeration” type. It describes how RTC users can create dependent list’s programmatically in an RTC project area by reading dependent relationships from any source in a defined format. This helps RTC users save the time of doing manual updates for such configurations, especially in situations when similar changes are required to be done in many project areas.
Overview
RTC is a tool used for change control management. A single RTC server may host multiple project areas. Each project area in turn has multiple attributes, based on project need. The various types of attributes available in RTC are text, numbers, enumerations, etc.
Enumeration attributes are of the list type, in which a set of predefined values are displayed for user choice e.g. severity, priority. Project administrators may create additional custom enumerated attributes and their lists. RTC allows a provision where one enumerated attribute may be made dependent on another enumerated attribute (driver attribute). Here, the list of values displayed for a dependent attribute is filtered on the value chosen in the driver attribute. Generally these dependency relations are usually defined by the organization’s process group. Below is an elaboration with example, explaining enumeration dependency relationship.
Elaboration of the enumeration dependency relationship:
In this example, ODC (Orthogonal Defect Classification) attributes have been used for explaining enumeration dependency relationship. ODC attributes are used for capturing information needed for root cause analysis. This information helps in improving project process, with the goal of minimizing defect count.
In the ODC template there are multiple ODC attributes. For detailed understanding of the ODC template please refer to the ODC reference link provided below. In the enumeration dependency example below we have used a couple of ODC attributes, namely targetODC and deftypeODC.
targetODC attribute is used to capture high level of entity that was fixed. e.g values for targetODC are requirements, build, information etc.
deftypeODC attribute is used to capture the actual correction that was made. e.g., values for deftypeODC are Initialization, Checking, Function, Editorial, Technical etc.
As we see from the attribute explanations, before making any correction (fix), we identify the target area first i.e. is it a defect from requirements, build, information etc. Fix to be done would vary based on the target identified. As a requirement defect might need a fix in the algorithm whereas an information defect might need a fix in editorial. Thus a fix can only be applied once the high level entity to be fixed is identified.
Hence we see that deftypeODC attribute is dependent on targetODC attribute. deftypeODC values get refreshed depending upon the value chosen for targetODC. Refer to the image below, depicting the value changes in ODC Defect Type based on ODC Target chosen.
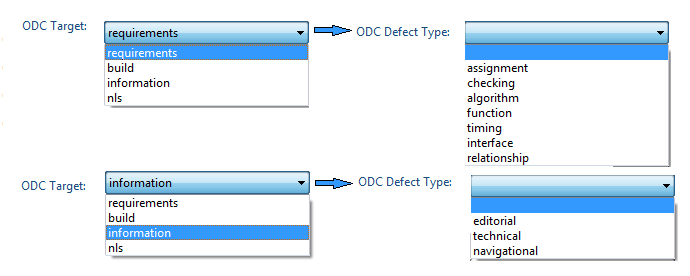
Figure: On choosing “requirements” for the enumeration attribute “ODC Target”, the allowed values for “ODC Defect Type” are populated. Similarly on changing “ODC Target” to “information”, different set of values are populated for “ODC Defect Type”.
Manual Mode of creating enumeration dependency:
RTC provides a UI for adding dependencies among enumerated literals. For setting up custom enumerations through GUI refer to the link provided in the reference section.
Manual mode of adding dependencies helps if project customizations for enumerated literals are small, but it becomes challenging when large numbers of enumerated literals need to be created. Another challenge could be in situations where project area is configured based upon enumerated values from another system. Any change in the source system would require manual updates in RTC project area.
Programmatic way of creating enumeration dependency with their benefits:
Using available RTC APIs, challenges in UI approach can be resolved with ease. Starting step is reading dependency relationship between enumerations from any file (or any other source). An example of dependency file structure has been shared in the section below. These dependency relations are then replicated in RTC, using RTC project area xml and RTC API.
The benefits achieved with API approach are:
- Dependency addition for larger number of enumerated attributes can be done easily.
- Dynamic setup based on any dependency relationship available in the underlying system. This eliminates RTC admin overheads of reading values from an existing system and replicating it on RTC server and also decreasing chances of human error.
- Reuse factor of enumeration dependency script, makes it a smart one-time investment. Multiple project areas may be easily configured for same or different enumerated dependency set.
Detailed Programmatic Solution of creating dependency amongst enumerated attributes:
RTC provides APIs using which current RTC project area process configuration can be read, modified and saved for any enumerated field setup. Details for these are described below.
Reading project area XML:
Getting the XML of the project area requires following steps to be performed:
a. Getting the process area from project area handle:
First get an instance of the IProcessItemService:
IProcessItemService processItemService = (IProcessItemService)teamRepository.getClientLibrary(IProcessItemService.class);
Now, get the process area reference:
IProcessItemService processItemService = (IProcessItemService IProcessArea processArea = (processItemService.findProcessAreas (teamRepository.loggedInContributor(), projectAreaHandle, IProcessClientService.ALL_PROPERTIES, monitor)).get(0);
b. Get the working copy manager, and connect it to the processArea:
IWorkingCopyManager workingCopyManager = ((IProcessItemService) teamRepository.getClientLibrary (IProcessItemService.class)).getWorkingCopyManager(); workingCopyManager.connect(processArea);
c. Get the working copy of the project area:
IProcessItemWorkingCopy processItemWorkingCopy = workingCopyManager.getWorkingCopy(processArea); IProjectAreaWorkingCopy workingCopy = (IProjectAreaWorkingCopy) processItemWorkingCopy;
d. Now, get the project area XML from the working copy’s process specification.
IDocument document = workingCopy.getProcessSpecification(); String projectAreaXml = document.get();
Fetching dependency values from a source system:
In this example, we are assuming that the relations are present in a text file. The structure for storing the dependency relations is assumed to be:
driverAttributeName|driverLiteral|dependentAttributeName|dependentLiteral
In the text file, each row represents a part of the driver-dependent relationship. For example, in the following example, the applicable values for the ‘deftypeODC’ attribute if the literal ‘nls’ is chosen for the driver field ‘targetODC’: [translation, handling, UI, enablement, expectation].
targetODC|nls|deftypeODC|translation
targetODC|nls|deftypeODC|handling
targetODC|nls|deftypeODC|UI
targetODC|nls|deftypeODC|enablement
targetODC|nls|deftypeODC|expectation
Creating value set providers
XML representation of value set providers
After fetching values to be added in RTC as driver and dependent field explained above, we first need to create providers defining the relationship between each such driver and dependent e.g. if ODC target attribute is driver field for ODC deftype and ODC content attribute, then we need to create two value set providers for both these relationships .
Data tag of project area xml has different configurations like that of workitem types, enumerations, workflows etc .Similarly we need to have a separate configuration data for creating value set providers.
xmlns and id to be used for creating value set providers would be as follows
<configuration-data xmlns="http://com.ibm.team.workitem/providers" id="com.ibm.team.workitem.configuration.providers"> </configuration-data>
After defining configuration data create the parent valueSetProviders tag and start writing all provider required. Each provider will have three properties namely id, name, providerId .Here id and name can be any meaningful name for your provider (The id will be used to associate provider with its attribute definition, explained in next step) and p roviderId will be “com.ibm.team.workitem.common.internal.attributeValueSetProviders.FilteredValueSetProvider”
<configuration-data xmlns="http://com.ibm.team.workitem/providers" id="com.ibm.team.workitem.configuration.providers"> <valueSerProviders> ]<valueSetProvider id="suggestedTargetODC" name="SuggestedTargetODC" providerId="com.ibm.team.workitem.common.internal.attributeValueSetProviders.FilteredValueSetProvider"> </valueSetProviders> </configuration-data>
Add filterMap as child element of valueSetProvider tag and and write dependentEnumeration and sourceEnumeration. The name of these enumerations should be same as type of these attributes from their attributeDefinition
<attributeDefinition id="targetODC" name="ODC Target" type="targetODC"/> <enumeration attributeTypeId="targetODC " name="targetODC "> <literal id="targetODC.literal.l1" name="nls"/> <literal id="targetODC.literal.l2" name="information"/> <literal id="targetODC.literal.l3" name="requirements"/> <literal id="targetODC.literal.l4" name="build"/> <literal default="true" id="targetODC.literal.l10" name=""/> </enumeration>
The filterMap with source and dependent name will look like this
<configuration-data xmlns="http://com.ibm.team.workitem/providers" id="com.ibm.team.workitem.configuration.providers"> <valueSerProviders> <valueSetProvider id="suggestedTargetODC" name="SuggestedTargetODC" providerId="com.ibm.team.workitem.common.internal.attributeValueSetProviders.FilteredValueSetProvider"> <filterMap dependentEnumeration="deftypeODC" sourceEnumeration="targetODC"> </valueSerProviders> </configuration-data>
Now comes the part to add the literals values from dependent field and the literal value of driver field on which it depends.
Eg if targetODC field value is ‘nls’ , defTypeODC can only have five fields namely ‘translation’,’handling’,’UI’,’enablement’,’expectation’ and if targetODC is ‘informaton’ defTypeODc can take any of these fields ‘editorial’,’technical’,’navigational’ only.
<configuration-data xmlns="http://com.ibm.team.workitem/providers" id="com.ibm.team.workitem.configuration.providers"> <valueSerProviders> <valueSetProvider id="suggestedDeftypeODC" name="suggestedDeftypeODC" providerId="com.ibm.team.workitem.common.internal.attributeValueSetProviders.FilteredValueSetProvider"> <filterMap dependentEnumeration="deftypeODC" sourceEnumeration="targetODC"> <value content="targetODC.literal.l1"> <literal id="triggerODC.literal.l4"/> <literal id="triggerODC.literal.l8"/> <literal id="triggerODC.literal.l15"/> <literal id="triggerODC.literal.l2"/> <literal id="triggerODC.literal.l1"/> </value> <value content="targetODC.literal.l2"> <literal id="triggerODC.literal.l3"/> <literal id="triggerODC.literal.l6"/> <literal id="triggerODC.literal.l7"/> </value> </filterMap> </valueSetProvider> </valueSetProviders> </configuration-data>
The above piece of code is added to project area xml works well for one project area and limited attributes, but same can be achieved programmatically by some source system or file.
/** * Method to create value set provider by iterating over driver and dependents values. * @projectAreaXML: XML representation of project area * @dependencyRelations: The string representation of all driver literals and their corresponding dependent literals i.e list of all relations * 'driverAttributeName|driverLiteral|dependentAttributeName|dependentLiteral' */ private void createProvider(final Element el, final Document doc, final String projectAreaXML,final String dependencyRelations) throws ParserConfigurationException, SAXException, IOException { final Map<String, String> driverList = new HashMap<String, String>(); Element filterMap = null; final List<String> dependents = getDependents(dependencyRelations); //get list of all the dependents final Map<String, List<String>> driversAndValues= getDriversAndValues(dependencyRelations);// get map of all drivers and their values final String configData = "configuration-data"; final String id = "com.ibm.team.workitem.configuration.providers"; final String xmlns = "http://com.ibm.team.workitem/providers"; final DocumentBuilderFactory dbf =DcumentBuilderFactory.newInstance(); final DocumentBuilder db = dbf.newDocumentBuilder(); final Document doc = db.parse(new InputSource(new StringReader(projectAreaXML))); final Element docEle = doc.getDocumentElement(); final NodeList nl = docEle.getElementsByTagName("data");//search for 'data' tag within xml. final Element data1 = (Element) nodel.item(0); // Creating configuration-data tag and its attributes final Element cfgdata = doc.createElement(configData); //create the configuration-data tag final Attr attr1 = doc.createAttribute("xmlns");//add attribute xmlns attr1.setNodeValue(xmlns); final Attr attr = doc.createAttribute("id");//add attribute id attr.setNodeValue(id); cfgdata.setAttributeNode(attr1); cfgdata.setAttributeNode(attr); data1.appendChild(cfgdata); //Create valueSetProviders tag final Element e = doc.createElement(""valueSetProviders); cfgdata.appendChild(e); //Iterate for each driver and for each value of that driver, look for the allowed values of its dependents in dependencyRelations String for (final String driver : driversAndValues.keySet()) { final List<String> driverVals = driversAndValues.get(driver);// // get all values for the driver for (final String aDependent : dependents) {//iterate for each dependent for (final String aDriverVal : driverVals) {//iterate over each value of driver final List<String> allowedValues = getDependentValues(driver, aDriverVal,aDependent,dependencyRelations); if (allowedValues.size() > 0) { boolean flag = false; if (driverList.containsKey(driver)) { final String tmp = driverList.get(driver); final String arr[] = tmp.split("|"); if (arr.length == 2) { for (final String a : arr) { if (aDependent.equalsIgnoreCase(a)) { flag = true; break; }}//end if } else { if (aDependent.equalsIgnoreCase(tmp)) { flag = true;}}} // Create valueSetProvider tag and its attributes for the allowed values if (!flag) { final Element valueSetProvider = doc.createElement("valueSetProvider"); final Attr attr1 = doc.createAttribute("name"); attr1.setNodeValue("Suggested " + aDependent);//provider name valueSetProvider.setAttributeNode(attr1); final Attr attr = doc.createAttribute("id"); attr.setNodeValue("suggested" + aDependent); valueSetProvider.setAttributeNode(attr); final Attr attr2 = doc.createAttribute("providerId"); attr2.setNodeValue ("com.ibm.team.workitem.common.internal.attributeValueSetProviders.FilteredValueSetProvider"); valueSetProvider.setAttributeNode(attr2); el.appendChild(valueSetProvider); filterMap = doc.createElement("filterMap"); final Attr attr3 = doc.createAttribute("sourceEnumeration"); attr3.setNodeValue(driver); filterMap.setAttributeNode(attr3); final Attr attr4 = doc.createAttribute("dependentEnumeration"); attr4.setNodeValue(aDependent);// change it to constant filterMap.setAttributeNode(attr4); valueSetProvider.appendChild(filterMap); } final String literalId = getLiteralId(aDriverVal, driver, projectAreaXML);//get literal ids by sending literal name from project area xml if (literalId.trim().length() != 0) { final Element value = doc.createElement("value");//for each value in driver field final Attr attr5 = doc.createAttribute("content"); attr5.setNodeValue(literalId); value.setAttributeNode(attr5); filterMap.appendChild(value); for (final String dependentValues : allowedValues) {//add all dependents literals for selected driver literal final String literalID = getLiteralId(dependentValues, aDependent,projectAreaXML); if (literalID.trim().length() != 0) { final Element literal = doc.createElement("literal"); final Attr attr6 = doc.createAttribute("id"); attr6.setNodeValue(literalID); literal.setAttributeNode(attr6); alue.appendChild(literal); }}} if (!driverList.containsKey(driver)) { driverList.put(driver, aDependent);//avoid duplicate literal } else { final String val = driverList.get(driver); if (!val.contains(aDependent)) { final StringBuffer str = new StringBuffer(val); str.append("|"); str.append(aDependent); driverList.put(driver, str.toString()); }}}}}} /** * Method to create map of drivers and their values by parsing the string of dependencyRelations * Here, dependencyRelations is the text in the format: driverAttributeName|driverLiteral|dependentAttributeName|dependentLiteral */ public Map<String, List<String>> getDriversAndValues(String dependencyRelations) throws TeamRepositoryException { final Map<String, List<String>> driversAndValues = new HashMap<String, List<String>>(); final Map<String, String> dbColumnNamesOfDrivers = new HashMap<String, String>(); final List<String> finalList = new ArrayList<String>(); final String[] lines = dependencyRelations.split(System.getProperty("line.separator")); for (final String aResult : lines) { final String values[] = aResult.split("|"); final String driverKey = values[0]; final List<String> driverValues = new ArrayList<String>(); for (final String aLine : lines) { if (aLine.startsWith(driverKey)) { final String[] vals = aLine.split("|"); if (!driverValues.contains(vals[1])) { driverValues.add(vals[1]); } } } driversAndValues.put(driverKey, driverValues); } return driversAndValues; } /** * Method to get allowed values of dependent for a single value of driver field. * Here, dependencyRelations is the text in the format: driverAttributeName|driverLiteral|dependentAttributeName|dependentLiteral */ private List<String> getDependentValues(final String driverName, final String driverValue, final String dependentName, final String dependencyRelations) { final List<String> dependentValues = new ArrayList<String>(); if (dependencyRelations != null && dependencyRelations.length() > 0) { final String[] lines = dependencyRelations.split(LINE_SEPARATOR); for (final String aResult : lines) { final String[] values = aResult.split(PIPELINE); final String literalToAdd = values.length <= 3 ? "" : values[3]; if (values[0].equals(driverName) && values[1].equals(driverValue) && values[2].equals(dependentName) && !dependentValues.contains(literalToAdd)) { dependentValues.add(literalToAdd); }}} else { throw new IllegalArgumentException("Dependency relations can not be null."); } return dependentValues; } /** * Method to get dependents list by parsing the string of dependencyRelations * Here, dependencyRelations is the text in the format: driverAttributeName|driverLiteral|dependentAttributeName|dependentLiteral */ public List<String> getDependents(final String dependencyRelations) { final List<String> dependents = new ArrayList<String>(); for (final String aResult : dependencyRelations.split(LINE_SEPARATOR)) { final String values[] = aResult.split(PIPELINE); if (!dependents.contains(values[2])) { dependents.add(values[2]); } } return dependents; } /** * Method to read literal id from literal names from project area xml. */ private String getLiteralId(final String newVal, final String newField, final String projectAreaXML) { String id = ""; final String enumTag = "enumeration"; final String attTypeId = "attributeTypeId"; inal String enumConfigId = com.ibm.team.workitem.configuration.enumerations"; final String configData = "configuration-data"; final DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); final DocumentBuilder db = dbf.newDocumentBuilder(); final Document doc = db.parse(new InputSource(new StringReader(projectAreaXML))); final Element docEle = doc.getDocumentElement(); final NodeList nl = docEle.getElementsByTagName(configData);//look for configuration-data tag if (nl != null && nl.getLength() > 0) { for (int i = 0; i < nl.getLength(); i++) { final Element el = (Element) nl.item(i); if (el.getAttribute(ID).equals(enumConfigId)) { final NodeList nlChild = el.getElementsByTagName(enumTag);//look for enumeration tag if (nlChild != null && nlChild.getLength() > 0) { for (int j = 0; j < nlChild.getLength(); j++) { final Element childEle = (Element) nlChild.item(j); if (childEle.getAttribute(attTypeId).equals(newField)) {// search for attribute in enumeration list final NodeList literals = childEle.getElementsByTagName("literal"); for (int k = 0; k < literals.getLength(); k++) { final Element literal = (Element) literals.item(k); if (literal.getAttribute("name").equalsIgnoreCase(newVal)) {//search for literal with given name id = literal.getAttribute("id"); break; }} }}}}}} return id;//return the literal id } Open project area XML for editing and then look for tag name data. Add configuration tag and its attributes xmlns and id, create value set providers and add value set provider for one set of relationship between drivers and dependents .Give name and if for provider and create filter map defining source and destination enumerations. Add value content and its dependent value literals.
Note: Another check required here is to check for pre-existing tags for cases when some provider already exists or the code to create providers is run more then once. So when looking for tag data in project area xml, a search for configuration data with same id and xmls can be made to ensure it doesn’t exist. If it exist then search for value set provider with same source and destination enumeration. If found this can be deleted and added again and if only configurations exist but provider doesn’t exist, add new provider.
Adding these providers to the driver fields
The provider created above has to be added to attributeDefinition of dependent field also. Add dependsOn tag with id of driver attribute (targetODC in this case) and then write the providerId of provider in the attributes of valueSetprovider tag. Add filterAttribute tag as children of valueSeProvider and again write id of driver field.
<attributeDefinition id="deftypeODC" name="ODC Defect Type" type="deftypeODC"> <dependsOn id="targetODC"/> <valueSetProvider providerId="suggestedDeftypetODC"> <filterAttribute id="targetODC"/> </valueSetProvider> </attributeDefinition>
Sample code to perform the above steps
/** * Method to add providers to attribute definition. */ private void addAttributeDefinition(final String projectAreaXML, final Map<String, String> driverList, final Document doc){ final Element docEle = doc.getDocumentElement(); final NodeList nl = docEle.getElementsByTagName("attributeDefinition");//get the attributeDefinition tag if (nl != null) { for (final Map.Entry<String, String> map : driverList.entrySet()) {// for each drivers final String driver = map.getKey(); String dependent = ""; final String arr[] = map.getValue().split("|"); if (arr.length < 2) {// if one driver has multiple dependents split them for each dependent = map.getValue(); createNode(projectAreaXML, dependent, driver, nl, doc); } else { for (final String element : arr) {//create node to add dependsOn for each attribute found createNode(projectAreaXML, element, driver, nl, doc);}}}}} /** * Method to create dependsOn node for each attribute */ private void createNode(final String projectAreaXML, final String dependent, final String driver, final NodeList nl, final Document doc) { for (int i = 0; i < nl.getLength(); i++) { final Element el = (Element) nl.item(i); if (dependent.equalsIgnoreCase(el.getAttribute("type"))) { final String driverId = getIDForType(driver, projectAreaXML); final Element depend = doc.createElement("dependsOn"); final Attr attr = doc.createAttribute(ID); attr.setNodeValue(driverId); depend.setAttributeNode(attr); el.appendChild(depend);// add value set provider final Element valueSetProvider = doc.createElement("valueSetProvider"); final Attr attr1 = doc.createAttribute("provierId"); attr1.setNodeValue("suggested" + dependent); valueSetProvider.setAttributeNode(attr1); el.appendChild(valueSetProvider);// add filterAttribute final Element filterAttribute = doc .createElement("filterAttribute"); final Attr attr2 = doc.createAttribute("id"); attr2.setNodeValue(driverId); filterAttribute.setAttributeNode(attr2); valueSetProvider.appendChild(filterAttribute); break;}}} Saving Project Area:
Saving the project area XML requires following steps:
a. Formatting the generated XML:
final TransformerFactory tf = TransformerFactory.newInstance(); final Transformer tfm = tf.newTransformer(); tfm.setOutputProperty(OutputKeys.INDENT, YES); tfm.setOutputProperty({http://xml.apache.org/xslt}indent-amount, "4"); final DOMSource source = new DOMSource(document); final StreamResult result = new StreamResult(new StringWriter()); tfm.transform(source, result); projectAreaXml = stringWriter.toString(); b. Saving the XML:
workingCopyManager.connect(processArea); document.set(newXML); processItemWorkingCopy.save(monitor); workingCopyManager.disconnect(processArea);
For more information
- Creating enumerated custom attributes (Refer to Rational Team Concert and defect data classification section in the link)
- Adding Dependency between enumerations through UI (Refer to Dependent Enumeration section in the link)
About the authors
Atul Kumar is part of Rational Corp Tools team at IBM Software Labs in India where in he is developing RTC integration with IBM legacy systems. He holds a master’s degree in software engineering having around four years of experience in network management and configuration management systems. He can be contacted at atulkumar@in.ibm.com
Megha Mittal is also part of Rational Corp Tools team at IBM Software Labs, in India and working on RTC integrations with IBM legacy systems. Megha holds a master’s degree in computer applications and has seven years of experience in application development, primarily in Java technology. She can be contacted at mmittal1@in.ibm.com
Siddharth Kumar Saraya is working as Technical Lead for IBM Rational. He has completed Dual Masters degree, one in Computer Application and second in Business Administration with majors as Risk and Insurance Management. A summary of the experiences gained over the number of years are manual, automation testing, involved in delivery of projects and managing project teams from project initiation till deployment. He can be contacted at Siddharth.Kumar.Saraya@in.ibm.com
Copyright © 2012 IBM Corporation