High availability and disaster recovery for Rational's Collaborative Lifecycle Management products
Table of contents
Background
High availability
High availability versus disaster recovery
Network flexibility
Work in progress, future directions
Clustering
High availability at the database server
Summary
Background
As deployments of Rational's Jazz products become larger and support a larger community of users, and the delivery of software and systems becomes more and more critical to enterprise success, demands for availability of the CLM systems increase dramatically. For this reason, IBM Rational takes the High Availability and Disaster Recovery capabilities of the CLM products very seriously. In this article, we will discuss the concepts of High Availability and Disaster Recovery, identify the currently available options for achieving these qualities of services, and also discuss some of the future capabilities we are pursuing.
We are openly discussing our desires and intentions in order to help you plan for the future and to get your feedback. That said, things do change, and we cannot guarantee that these future features will be delivered exactly as described.
High availability
High Availability is defined in Wikipedia as “a system design approach and associated service implementation that ensures a prearranged level of operational performance will be met during a contractual measurement period.” It is usually implied that the desired level of availability is very high, with low to zero planned unavailability.
Increased availability is achieved by having redundant providers of a service or capability. Ideally, the failover from one provider to another is transparent to the user or client of a service, but in some cases a failure of a primary provider will require a manual switch. Rational Team Concert pioneered High Availability for Jazz products in its 2.0 release with an “idle standby” solution, described here. This year we have broadened support to all of the current CLM products. The details are described in this article in the InfoCenter.
How does this solution work for CLM, and what are the limitations? We won't go into all of the details here, but the basic solution looks like this:
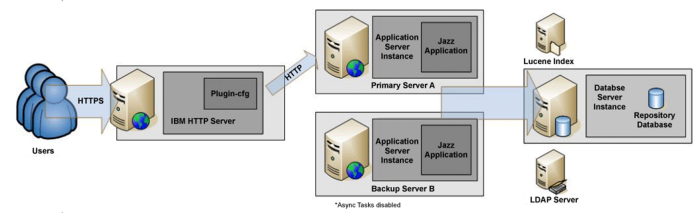
For each application server in the primary topology, a redundant server is deployed. They are configured identically, talking to the same database server. The actual names of these servers are hidden, from a Jazz perspective they each pretend to be the same public URI. An HTTP server in front of the servers implements that actual public URI and is aware of the primary and backup servers. It normally routes requests to the primary server, but can be configured to route to the backup in case of a failure.
Today, failover must be done manually, for safety reasons. It's vital that only one Jazz server talk to the repository database at any time. If two servers were connected, and taking requests, they would be making bad assumptions based on cached data, and could make inconsistent changes to the database. If a primary server crashes or appears unresponsive, an administrator needs to ensure that it is no longer connected to the repository database before routing traffic to the backup server.
In the original HA support for RTC, we suggested an “idle standby” solution, where the backup server was running but not connected to the database, and this required a couple other tweaks to ensure a safe failover. We've since investigated a “cold standby” where the backup server is started, but the Jazz application is stopped. This appears to be a better solution; since the backup server needs fewer configuration tweaks and the chances of a request accidentally activating the backup server is reduced. In fact, it is the only supported option for the RM application. Details are in the InfoCenter article above.
We understand manual failover is not ideal, but you can see that there are real issues with enabling automated failover. Later on, we will talk about what we're doing to get there.
What about High Availability at the database level? The “truth” in a CLM installation is held in the relational database that stores the repository data. An airtight High Availability solution would need to ensure that your database server is also highly available. However, in practice, we find that a commercial database running on robust hardware is inherently extremely reliable. At jazz.net, for example, we support all of the development of the CLM products and host our community relying on a robust non-redundant database layer. That said, if you have needs for extreme High Availability, there are solutions available to achieve redundancy at the database layer. The solution that is currently documented and supported is DB2's High Availability and Disaster Recovery (“HADR”) solution. This solution, described in this jazz.net article, provides a topology like so:
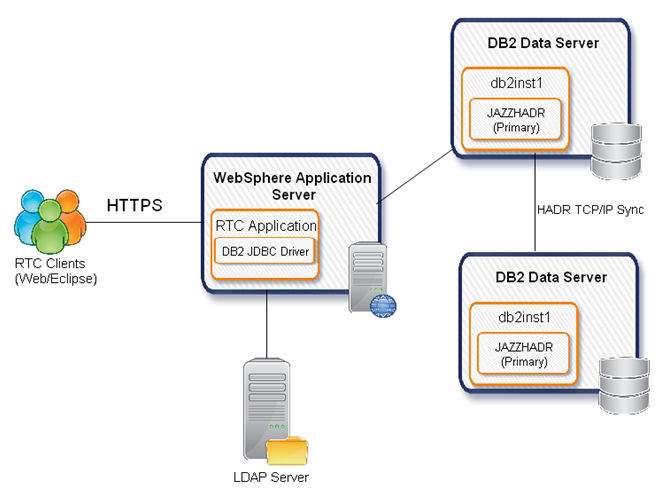
Here we have redundant database servers linked via a TCP/IP synchronization protocol. A proxy routes to the available server.
Other vendors provide similar solutions, and we have anecdotal evidence of customers running with Oracle RAC and SQL Server clusters, but we have not officially tested those configurations. The way these solutions work is generally transparent to the database application, so we expect them to just work. We did not identify any issues or make any changes to support the DB2 HADR solution, for example.
High availability versus disaster recovery
Disaster Recovery is a concept that often comes up when discussing High Availability. You can see that the DB2 solution above intertwines the two concepts. For the same reason that availability of your CLM servers is vital as you support larger and larger teams, and more and more projects, it is increasingly important that your CLM data is safe from corruption.
Disaster recovery is defined by Wikipedia as “the process, policies and procedures related to preparing for recovery or continuation of technology infrastructure critical to an organization after a natural or human-induced disaster. Disaster recovery is a subset of business continuity.” Where High Availability is about keeping your server available as much as possible, Disaster Recovery is about making sure you have the data to put it back together if the worst happens.
For the CLM products, disaster recovery starts with a backup strategy. Basic backup techniques are discussed in the InfoCenter here. Use the best online backup capability of your database vendor to produce frequent backups. There are critical configuration and index files that should be part of your backup strategy as well. Indexes can generally be recreated from the database, although large indexes can be time-consuming to rebuild, so if you have to make a choice, prioritize the backup or DR solution for your database. Depending on your service level needs, you can then ship those backups offsite. Solutions like DB2 HADR can be used to achieve HA and DR by replicating offsite in near real-time.
Network flexibility
Designing for network flexibility is another topic not strictly related to HA/DR, but worth considering as you are designing your CLM deployment. At the moment, it is not possible to move or rename a CLM server, to move projects between servers, or to change the Jazz Team Server with which a CLM application is associated. We know these are real pain points, and we're working on easing them.
In the meantime, it's worth doing a little bit of extra planning to give yourself some flexibility in the future should your network topology have to change. There's a good discussion of the considerations in planning your sever URIs here in the InfoCenter. The bottom line is that you don't want to expose the physical URI of your Jazz applications directly to clients, or even other CLM servers, if you can avoid it. Using virtual hosts for applications, or using an HTTP proxy to route requests, will allow you the ability to change the physical location later on. The public URI still has to be stable, though. It's also a good idea not to include any geographical element in host names, so that they can be resolved anywhere in the network and can be physically relocated.
Here is an example topology using a reverse proxy to “hide” the physical servers in a CLM topology:
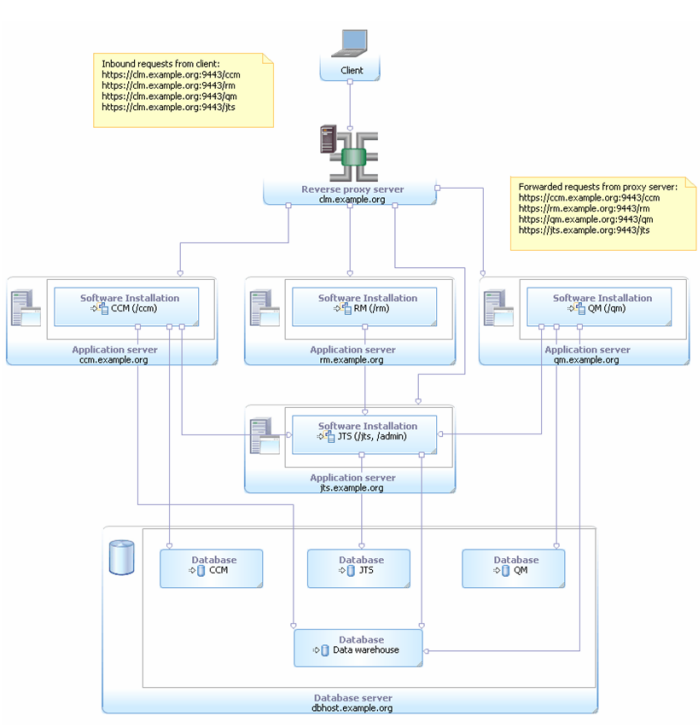
Using a reverse proxy in this example gives us future flexibility to deploy applications to different physical or virtual servers. We've also simplified the client view of the physical deployment by hiding the fact that there are four applications servers behind the single virtual host. All application connections and stored references are done via the public URIs exposed at the proxy.
There is more detail regarding configuring a reverse proxy using the IBM HTTP Server here in the InfoCenter.
Work in progress, future directions
As we mentioned earlier, we'd like to describe our goals for further enhancing the HA capabilities of the CLM products. These are our best guess at the next steps we will take to improve our High Availability support, but these plans are subject to change.
Clustering
Our next step for making a dramatic improvement in High Availability will be to add support for clustering, which will enable hot failover to redundant servers. We've actually been working on this support for more than a year. In fact, clustering support is already available as a Tech Preview for the Jazz Team Server (JTS) since RTC 3.0.
The design for clustering is to take advantage of the ability of WebSphere, and potentially other application servers later on, to configure a group of like servers, and to load balance client requests across those servers. With this topology, individual servers can come and go without disrupting service to clients. Like the HA configuration above, clients talk to the load balancer and aren't aware of the names of the individual servers in the cluster.
In a cluster, all of the application servers will share the same database server, possibly a clustered DB server, and will run their own copies of the CLM applications. Sharing the database ensures that the applications all work from the correct persistent state, and if the applications were completely stateless, the job would be done. In practice, the applications are mostly stateless, they have to assume the database holds the truth, but they may cache some modified data at any point in time. In order for the cluster to behave consistently, and avoid making an incorrect update to the database, we need the application instances to share this state across the cluster. We have implemented this by using the ObjectGrid capability of WebSphere eXtreme Scale. The cluster topology for Jazz looks like this, using a simplified example of just clustering the Jazz Team Server:
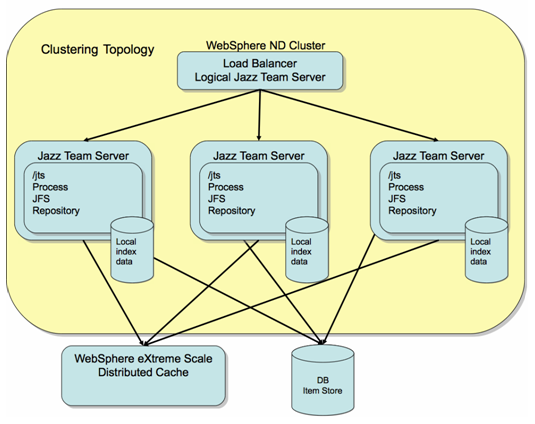
You can see that each of the applications rely on a shared database for the repository database, but they have some local index data which they maintain, and they also use the Distributed Cache to share “in memory” state.
Last year, we added the Distributed Cache to the system, and we did the work to analyze all of the services of the Jazz Team Server, and to make them stateless or to store any cached state in the distributed cache. We ran automated tests against clusters of JTS servers to debug and prove the basic architecture.
This year we are continuing this work, having identified a few more issues in the JTS. Our goal is next to self host on a cluster of JTS servers. At the same time, we are beginning the analysis and testing work on the other applications: CCM, RM, and QM to make them cluster-friendly. We'll self host on that as part of our testing of the next CLM release, and our hope is to declare support for clustering in 2012.
As part of delivering clustering capability, we will provide support and instructions for evolving an existing topology into a cluster. We understand that as deployments grow, the requirements on HA increase, and this would be a natural evolution path.
Due to the complexity of setting up and testing clustering topologies, we will only support clustering with WebSphere, at least initially. Technically, the hard work will be done to support clustering with other app servers. We will include and install the necessary WebSphere eXtreme Scale components to support clustering, but it may be necessary to buy additional WXS licenses to support larger clusters or multi-datacenter topologies. There are other advantages of using WebSphere to run a cluster. A clustering and load balancing configuration is inherently complex, and the WebSphere administrative console and tools provide support for configuring and managing such a topology.
You can track our progress on clustering support by following plan item 103973.
What about scalability, isn't clustering also an approach to enable horizontal scalability? Yes, this is true, but our first focus with clustering is to enable High Availability. There will actually be places where we may have to trade off some single-server throughput in order to make services stateless and leverage the distributed cache. For the CCM and QM applications, the shared database usually becomes the performance bottleneck, so scaling it vertically or horizontally is more useful than horizontal scaling of the applications and we don't expect dramatic scaling benefits from clustering. The RM application makes more use of some runtime query capabilities, and may see more benefit from load balancing across a cluster. We'll see when we get to our performance testing…
High availability at the database server
We mentioned that we currently support DB2's HADR as a solution for achieving High Availability at the database layer. We have a proposed item in our plans for 2012 to test and support additional vendor solutions. You can track our plans and progress via plan item 169186.
Summary
Hopefully this gives you a good idea of the current and planned capabilities for CLM regarding High Availability. Today, you can take advantage of idle or cold standby to achieve manual failover and improved availability. While you're at it, think about the network topology that you want to support in the future and consider managing that with a reverse proxy. Develop a robust (and tested!) backup strategy for basic Disaster Recovery. If you need to meet higher availability or disaster recovery goals today, and DB2 is your database, consider using DB2's HADR support to improve HA at the database layer.
In the future, we hope you can take advantage of WebSphere ND and eXtreme Scale to achieve hot failover and a new level of High Availability.
Copyright © 2011 IBM Corporation