r14 - 2017-07-12 - 14:38:01 - Main.fryerkYou are here: TWiki >  Deployment Web > DeploymentPlanningAndDesign > CLMUsageModelBestPractices > CLMCfgMRecommendedPractices
Deployment Web > DeploymentPlanningAndDesign > CLMUsageModelBestPractices > CLMCfgMRecommendedPractices
Best practices for CLM/CE global configuration management 
Authors: KathrynFryer, TimFeeney Build basis: IBM Collaborative Lifecycle Management (CLM) and IoT Continuous Engineering (CE) 6.x (some comments apply to specific versions)
New configuration management capabilities were introduced in the IBM Rational solution for Collaborative Lifecycle Management (CLM) 6.0.0 and the associated IBM Internet of Things Continuous Engineering (IoT CE ) solution, extending the ability to version artifacts and define streams and baselines to the requirements and quality management domains.
This article captures practices for clients planning to adopt these new capabilities, based on IBM and client experiences to date. (Note: This article does not address source code configuration management (SCM), which has already evolved its own set of practices over a longer period of very broad use.)
Each project area or component has a single stream. Practitioners create change sets to deliver changes to the stream. A change set might be at the level of a feature, or a project, depending on the organization and defined scope. Any conflicts are resolved at change set delivery. Take baselines to capture the state at specific milestones (e.g. iterations, releases). Note: you might also choose to take a baseline after each change set delivery, as described below.
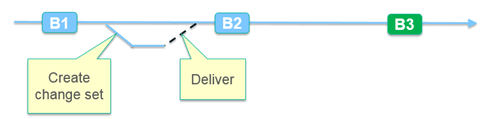 This is the simplest strategy. It requires no cross-stream deliveries. However, it can be limiting if many teams must work in parallel, on different cadences, with interleaved dependencies.
Note: The QM application does not yet support change sets. For QM streams, you can make changes directly to the stream and take baselines after each substantive change.
Production and integration streams, with separate release streams
This is the simplest strategy. It requires no cross-stream deliveries. However, it can be limiting if many teams must work in parallel, on different cadences, with interleaved dependencies.
Note: The QM application does not yet support change sets. For QM streams, you can make changes directly to the stream and take baselines after each substantive change.
Production and integration streams, with separate release streams
One main stream (trunk) represents the final production level. A parallel integration stream mirrors the main stream. Project or release work happens in a dedicated stream branched from the main stream; practitioners deliver changes to those dedicated streams. At defined intervals, project streams deliver their work to the integration stream. At defined intervals, changes from the integration stream are delivered to the main stream. Use baselines on all streams to capture content at specific milestones.
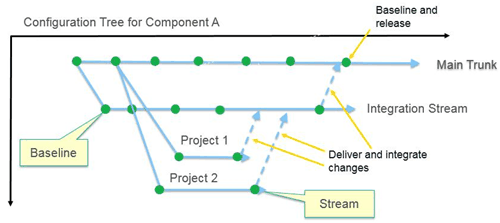 This strategy allows larger teams to work in parallel, using smaller change sets, and still be isolated from other teams' work. It can also provide tighter control over the production stream, since individual teams do not deliver there directly. It also requires greater coordination and management, and the cross-stream deliveries from multiple streams increase the potential for conflicts. There might also be a need to refresh project streams if they depend on deliveries from other streams that happen after the original branching.
This strategy allows larger teams to work in parallel, using smaller change sets, and still be isolated from other teams' work. It can also provide tighter control over the production stream, since individual teams do not deliver there directly. It also requires greater coordination and management, and the cross-stream deliveries from multiple streams increase the potential for conflicts. There might also be a need to refresh project streams if they depend on deliveries from other streams that happen after the original branching.
General adoption guidance
As you plan your adoption, it's important to consider your objectives and current processes, as well as these practices. Evaluate the capabilities in the context of end-to-end scenarios for your organization, including:- Component architecture and configuration strategy
- Stream strategy, including baseline creation, cross-stream delivery
- Change management, especially with respect to change sets
- Reporting needs
- Integrations with other applications
- Roles and permissions and other process aspects
Suggested best practices
The following sections provide guidance on different topics of consideration for adoption planning. These practices are based on experiences of clients who have already adopted configuration management.Defining components and configurations
At its simplest, a component is a container of artifacts. Configurations exist at the level of a component (that is, a component has one or more configurations). Components exist in the local applications (RM, QM, DM, SCM) and also at a global level in the GCM application. Global components are the basis for global configurations, which group the "local" configurations from the individual application components, and also other global configurations, to create hierarchical representations of your subsystems, systems, and offerings. In versions 6.0.0 through 6.0.2, each RM, QM, or DM project area represented a single component. As of version 6.0.3, you can optionally subdivide RM and QM project areas into smaller components, each with its own set of artifacts; each component has its own streams and baselines. Be aware of the following limitations related to components in 6.0.3:- To link between artifacts in different components, both component configurations must be included in the same global configuration.
- You can link between RM components, and RM and QM components, but you cannot link between individual QM components. To reuse an artifact across QM components, you must create a new copy.
- If two RM components each contain a version of the same artifact, you cannot include both components in a single global configuration, because it would introduce version skew. When you clone artifacts across components, you create a new version of the same source artifact in the target component; ensure that you will not include both source and target components in the same configuration. If you must include both components in a configuration, copy the artifact instead of cloning it: copying creates a new artifact instead of a new version.
- Configuration comparisons and change delivery or merge operations occur in the context of a specific component. Once you subdivide an existing project area into smaller components, you will not be able to compare to baselines or streams on the original project area component, or deliver changes across component boundaries.
- Balance granularity and complexity in defining components, especially when creating multiple components in a project area
- Avoid very deep hierarchies of global components and configurations
- Use naming conventions for identification and differentiation
- Define and use a tagging taxonomy for global components and configurations
- Consider custom attributes on global configurations where appropriate
- Use a consistent type system across project areas, components, and streams within a domain
- Define external RDF URIs for types, attributes, enumeration values
Balance granularity and complexity in defining components, especially when creating multiple components in a project area
In general, components should reflect the logical hierarchy of your systems or applications. As of 6.0.3, you can subdivide RM and QM project areas into multiple smaller components, providing flexibility to evolve, baseline, and reuse those components separately. However, to link across components, you need a global configuration. A configuration lead must maintain the global configurations and ensure the correct streams or baselines for each component are included in the appropriate global streams or baselines, so the correct artifact versions remain together. As the number of individual components increase, managing the variations and maintaining currency becomes more challenging. As you define your components, consider:- Reuse and variance. What logical components are reused across multiple versions or variants of your offerings? These logical components are a good starting point for your global components and the components in your project areas.
- Lifecycle cadence. Are there sets of artifacts that evolve and mature on a different timeline from others? You can baseline a component separately, allowing you to freeze that set of artifacts while the artifacts in other components are still evolving.
- Ownership. Ownership is not likely a sole determining factor; however, one might expect a component to be owned by one or a small number of teams, as opposed to multiple teams owning multiple artifacts over a variety of components.
- Relationships and links between artifacts. Links between artifacts don't always mean they belong in the same component; you can link across components (with some limitations - see below). However, if artifacts are interrelated and evolve in tandem, consider whether they should be grouped together.
Avoid very deep hierarchies of global components and configurations
Related to the previous point, deep global configuration hierarchies require additional effort to maintain over time. Where practical, aim for a hierarchy with 3 to 5 levels. If the complexity of your systems or offerings requires a deeper hierarchy, plan for how your configuration leads will manage the hierarchy and configuration variation over time. With deeper hierarchies, ensuring appropriate naming and tagging conventions becomes even more important. If you do have deeper or more complex global configuration hierarchies, plan carefully how to use the available automation to generate new global baselines or new streams from baselines in the hierarchy. From the highest level in the hierarchy, you can generate a global baseline that creates new baselines in every global and local contribution in the hierarchy. You can also select multiple baselines that contribute to the global configuration and create new streams for them. Either of these operations can place high demand on the local applications to create the required baselines or streams. For deeper hierarchies, consider starting at a lower level in the hierarchy and use the automation incrementally, creating the new baselines or streams in smaller batches. If the operation still impacts a significant number of local configurations, perform it when application usage is light. Alternatively, create local baselines or streams in the local applications first, then replace them in the respective global configurations.Use naming conventions for identification and differentiation
Naming conventions are very important for configurations, streams, baselines, and also change sets. They make it easier for practitioners to understand what they are working on, and for configuration leads to understand relationships as well as differentiate the configurations based on date, variant, and so on. For components, use names that are meaningful to the practitioners and configuration leads. Where appropriate, make the names similar between local and global components so it's easy to determine relationships. (For example, if a global component groups contributions from a single RM and a single QM component, use similar names for all three so it's clear they go together). For configurations, make the "unit of variance" clear, whether that is geographical, time-based, milestone-based, and so on. There isn't a single right answer, it depends on your process and usage model. You might also choose to use custom attributes or tags to indicate variance between configurations; ensure that your choices still support the configuration lead's tasks (for example, and don't require them to check the attributes for multiple configurations with the same name to determine which is the one they need). Consider the length of the name, and where the unique part of the identifier appears. In some parts of the UI, long component and configuration names might get truncated; for example, long component names might be truncated in the application title banner. If the names differ only in the last few characters, users might have difficulty differentiating between them.Define and use a tagging taxonomy for global components and configurations
The GCM application currently displays global components as a flat list, which can be challenging to navigate if you have many components. Define a tagging taxonomy to classify your components in a way that's meaningful to your organization; that might be based on the level of decomposition (base, subsystem, system), geography, model year, or other values. You can then use those tags to filter and search for the appropriate global components, as well as in JRS reports on components. You can also add tags to global configurations in the GCM application. Typically you would want a different taxonomy than for your global components, to identify them based on the variation points and so on. As you define usage scenarios for finding, managing, and reporting on global configurations and components, consider the taxonomy that supports those use cases. Note: Currently, you cannot add tags to local configurations.Consider custom attributes on global configurations where appropriate
In the GCM application, like the RM application, you can define custom attributes and attribute values to assign to global components and configurations. This provides another way to identify or classify configurations in ways that are meaningful to your organization. You can also use the custom attributes in reports. Note: Currently, you cannot define custom attributes for local configurations. To include custom attributes in your reports, ensure you are reporting on a global component and its global configurations.Use a consistent type system across project areas, components, and streams within a domain
To enable cloning, linking, and reporting on artifacts across project areas and components, you need consistent types defined across those projects and components. This is particularly important in the RM domain, where type systems are specific to a project area, or in 6.0.3 to a component within the project area. In QM projects, you can also define custom attributes, which apply only within that project area (and in 6.0.3, to any components it contains), and category values as well. Also ensure your type system is also consistent across streams for any given component. Changing the types for one stream and not another can cause issues when you have to deliver or merge changes across streams. Where you truly need to vary the type system between components or streams, carefully plan how you will deliver changes to the types where necessary, and how to deliver across streams where the types don't match. To keep your type systems consistent, define and use templates when you create new project areas and components. In RM projects, you can also import a type system from an existing project area or component into another.Define external RDF URIs for types, attributes, enumeration values
It's also important to define RDF URIs for attributes, types, link types, and enumeration values defined in your project areas and components, especially where these are shared or common. Use the same URI for all equivalent resources; for example, define the same RDF URI for the "Satisfies" relationship in every RM project area or component. For another example, if you have the same Test Plan categories across QM projects or components, define the same RDF URI for equivalent categories. Ideally, define the URIs in your project area or component templates, so they are automatically included for new project areas or components created with that template. Cloning across components is dependent only on the consistent type system. However, for RM projects, cross-component and cross-project links will not work unless the link types and RDF URIs are defined consistently across both source and target. RDF URIs also make cross-component and cross-project reporting much easier, because Report Builder can use them to consolidate types, attributes, and values. If you are reporting across projects and do not use RDF URIs to express equivalence, you will see attributes or values for each individual RM component or project area, even if their names are the same; similarly, you will see separate categories and custom attributes for each QM project area that defines them.Defining your stream strategy
Your stream strategy encompasses a number of aspects:- The main stream or streams that you will use
- How you deliver changes to your working stream and across streams if required
- When and how you take baselines, at both local and global levels
- When to branch a stream
- When to archive a configuration
- Define the simplest stream strategy that can meet your needs
- Use explicit change sets where possible, with meaningful naming conventions
- Deliver changes early and often
- Minimize cross-stream deliveries to reduce merge conflicts
- Define a baseline strategy
- Archive configurations and components when you no longer need them
Define the simplest stream strategy that can meet your needs
In general, define the simplest stream strategy with the fewest number of streams that meets your needs. As the number of streams increases, so does the effort associated with differentiating, managing, and delivering change across them. Some clients work with a single ongoing stream, where they deliver change over time and take baselines to capture the state at particular milestones. Others maintain a production stream, delivering changes first into an integration stream and then at defined intervals into production. Others require more than one integration stream to support separate projects working in parallel that must remain isolated. In some cases, that isolation can be handled with change sets. It's important to work through your own process and understand your organization's needs to decide the best strategy for you. Start your planning with the expectation of having a single stream, and then expand as you identify the need. Consider and plan for exceptional circumstances, but optimize for the typical and daily usage patterns. Here are two examples of many possible stream strategies: Single ongoing stream with change sets and baselinesEach project area or component has a single stream. Practitioners create change sets to deliver changes to the stream. A change set might be at the level of a feature, or a project, depending on the organization and defined scope. Any conflicts are resolved at change set delivery. Take baselines to capture the state at specific milestones (e.g. iterations, releases). Note: you might also choose to take a baseline after each change set delivery, as described below.
This is the simplest strategy. It requires no cross-stream deliveries. However, it can be limiting if many teams must work in parallel, on different cadences, with interleaved dependencies.
Note: The QM application does not yet support change sets. For QM streams, you can make changes directly to the stream and take baselines after each substantive change.
Production and integration streams, with separate release streams One main stream (trunk) represents the final production level. A parallel integration stream mirrors the main stream. Project or release work happens in a dedicated stream branched from the main stream; practitioners deliver changes to those dedicated streams. At defined intervals, project streams deliver their work to the integration stream. At defined intervals, changes from the integration stream are delivered to the main stream. Use baselines on all streams to capture content at specific milestones.
This strategy allows larger teams to work in parallel, using smaller change sets, and still be isolated from other teams' work. It can also provide tighter control over the production stream, since individual teams do not deliver there directly. It also requires greater coordination and management, and the cross-stream deliveries from multiple streams increase the potential for conflicts. There might also be a need to refresh project streams if they depend on deliveries from other streams that happen after the original branching.
Branch streams only when you need them
Branch streams only as needed, and only when you are ready to start working in them, to ensure they reflect the most current artifacts in the parent stream.Avoid deleting versioned artifacts in multi-stream environments
Avoid deleting versioned artifacts in streams where there is a possibility of future cross-stream deliveries; deleted artifacts can impact dependencies and cause problems with future deliveries both into and out of the stream where they were deleted. If you need to indicate artifacts are not relevant to a certain configuration, alternative approaches could include changing the artifact state to an appropriate value, or moving the artifact to a special folder.Use explicit change sets where possible, with meaningful naming conventions
In RM and DM applications, use explicit change sets where appropriate. (Note: We are not addressing the SCM application, where the use of change sets is widely known and followed; the QM application does not yet provide change sets.) With explicit change sets, you can group related changes together, provide a meaningful name to describe those changes, and link the change set to a change request in a change management system -- all of which help you to understand what changes were made and why, and to easily deliver those changes to another stream if needed. Both RM and DM applications provide an option to mandate change sets, set at the individual stream level. Define a naming convention that will help you identify change sets and relationships between change sets. If you don't need to group or track changes, or deliver across streams, you might not need explicit change sets. Examples might include the initial set of work on a new project, or for a single requirements stream with no need for cross-stream delivery or associating changes to a particular work request. Ensure that you consider your process across the lifecycle to determine when explicit change sets are and are not needed.Define the granularity and desired scope of your change sets
Decide the granularity, size, and expected duration for RM and DM change sets. For example, do you have one change set per change request, per feature, per project? How long can a change set remain open? You might also decide to limit change sets based on number of artifacts modified. Use naming conventions to express the content of your change, and ensure it addresses the potential to have multiple related change sets.Define permissions for change sets
Define who has permission to create and deliver change sets. Some clients have very tight control over who can open a change set; others assign permission to any team member. In RM, you can also permit a user to deliver change sets for other users; you might choose to have a team focal point responsible for delivering all the change sets for the team, along with resolving any conflicts. Refer to Defining Roles and Permissions for more details on permissions.Link change sets to change requests in your change mangement system
If you use a change management system (like Rational Team Concert), link your change sets to work items to establish traceability from the request to the actual changes. This is particularly useful if you have multiple related change sets, to document the scope of change and also provide a reference for the change sets needed to propagate the change to another stream if required. You can also choose to use the approval process in the change management application, and to mandate change request approval before the change set can be delivered.Deliver DM change sets with the Rhapsody client
You can deliver change sets through the DM web client, but you are not able to view and compare the changes at delivery. Use the Rhapsody client for a richer set of compare and merge capabilities.Use other capabilities in QM to manage change
QM does not yet support change sets. To manage change in QM projects:- Take frequent baselines so you can easily restore the baseline or merge a previous version of an artifact.
- Limit the ability to merge and restore across streams by assigning permissions to a small number of individuals.
- As of 6.0.3, you can use the artifact version tree in QM to understand how a specific artifact has evolved and its versions.
- Use link validity to understand requirements change.
- Consider documenting or reporting on changes associated with a particular change request.
Deliver changes early and often
Incremental changes tend to be easier to address than very large merge operations. Ideally, change sets are relatively small for faster delivery, and delivered quickly, to reduce the potential for conflict with other change sets that might be underway at the same time. At this point in time, you can't easily identify conflicting changes until you deliver them. (The change set will show non-conflicting changes made to the parent stream; however, with the exception of tags, if the artifact changes in both the change set and the parent stream, the change set will not reflect the parent's changes). For some clients, small incremental change sets might not be appropriate. If you require larger change sets that remain open for a long period of time, determine how to address the need to synchronize your change set with changes that happen to the parent stream between the time you open your change set and the delivery. In some cases, clients choose to open a new change set on the current stream and re-implement their changes to avoid conflicts. If users will select the "automatic" change set delivery in RM, also define what rules they need to follow for conflict resolution; for example, should users always resolve conflicts manually, or are there certain attributes that should usually default to source or target. There is also some ability to script delivery of change sets.Minimize cross-stream deliveries to reduce merge conflicts
Minimize cross-stream deliveries, especially across multiple streams, which increase the likelihood of merge conflicts. At this time, there is no easy way to detect conflicting changes that happen in parallel streams, other than by a compare or delivery operation. Where you do need to deliver across streams, determine based on your process and needs:- When to use a "deliver" (source pushes to target) or "accept" (target pulls from source) approach in RM and DM (QM always starts a merge from the target). Accepting changes might provide greater control and allow a "gatekeeper" kind of approach to the target stream.
- When to use a "cascade" (stream A to B to C) or "broadcast" (stream A to B, A to C) approach; both are valid, depending on your usage model and the stream hierarchy. If you will need to resolve the same merge conflict in each stream, you might choose the "cascade" approach, to complete the merge once and not repeat it. If a main stream changes, a "broadcast" approach to all children might be more appropriate.
- Who will complete the delivery. Consider centralizing responsibilities for cross-stream merging to a particular team or individual who can become expert in the process.
Define a baseline strategy
You can take baselines in the individual applications for a particular configuration (component). Define when you need to take baselines for individual components, who is responsible for doing so, and the naming convention to use so you can easily identify the baseline. You also take baselines for global configurations to capture a holistic snapshot of your global components, systems, and offerings. Global baselines include baselines for each of the local configurations they contain. Again, decide when to take global baselines, who is responsible, and naming conventions to use. Also decide whether and when to use the automated recursion or manual staging methods to create the global baseline:- Automated recursion: In a global configuration, you can automatically generate a baseline for all of the local configurations that appear in its hierarchy, in any of the applications (GCM, RM, DM, QM, SCM). This is a convenient and relatively quick way to create a global baseline. However, it assumes that each contributed configuration is in an appropriate state to be baselined. In addition, it places demand on the individual applications; if the hierarchy is deep or contains many local configurations, the load could impact application performance. Ensure that you complete such operations during periods of light usage, or consider an incremental approach and create baselines at lower levels of the hierarchy that you can then manually add to the higher-level global configuration. See Avoid very deep hiearchies of global components and configurations for additional details.
- Manual staging: You can also stage a baseline for a global configuration, and manually replace each contribution with a baseline. This method is more time-consuming for the configuration lead, especially for large or deep configurations. It provides more control at the local application level to take baselines asynchronously and then provide them for global configuration use. Your strategy and naming conventions should address how a global configuration lead would know which local baselines to choose.
Take baselines as often as is practical
For the local applications, baselines are not expensive to take or to store. At this time, neither RM nor QM applications provide the ability to roll back changes; you can use baselines as an alternative to rollback. However, too many baselines can affect reporting performance, as well as usability when selecting the configuration context. As you determine your baseline frequency, ensure that you are not taking them more often than necessary, and that you archive baselines that are no longer needed. In RM, take a baseline after each change set delivery. If a change is in error, you can either compare to the previous baseline and create a new change set to change the artifact back, or generate a new stream from the baseline and replace your current stream with the new one (note that could have impact on other practitioners with open change sets on the original stream). In QM, take baselines after what constitutes a substantive change, for example, review or approval completion. You can merge changes from the baseline into the current stream, or restore the baseline and revert the entire stream to that previous state (which could impact other changes made since that baseline). Typically only a few users would have permission to complete those actions.Archive configurations and components when you no longer need them
Over time, the list of configurations can become quite long, especially if you are taking frequent baselines. A very large number of configurations can impact reporting performance, as well as impact usability when selecting a configuration context for reporting, comparison, cross-stream delivery, and so on. Periodically review the list of baselines to determine which are no longer required; for example, once you pass a release milestone, you might archive the interim baselines you took in between milestones. Also review the streams for your components, and archive those that have no ongoing work and are not a flow target for other streams. You can also archive an entire component, which archives all the configurations associated with that component. For example, if you have reorganized your project area into multiple components, you can eventually archive the original component as obsolete. You can archive and restore configurations and components at both the local and global level. You cannot archive a local configuration if other configurations created from it are still active. Archived global configurations still appear in other global configurations that reference them, although they are not included in search and filter results. The Knowledge Center provides more details on archiving global configurations and local configurations.Reporting on versioned artifacts
Reports and dashboard widgets that use the data warehouse will not work for versioned artifacts. For interactive reports on versioned artifacts, you need to use the Lifecycle Query Engine (LQE) data source and possibly rewrite a number of existing reports to use LQE. As part of your adoption planning, identify and prioritize the reports you need, and how you might obtain them. Plan and stage your reporting adoption along with the broader adoption, building reports as part of your evaluation and pilot activities.- Start by leveraging the reporting options that are easiest to adopt
- Follow recommended practices for reporting in general
- Use consistent type systems with external URIs
- For reusable reports, avoid limiting scope
- Use custom SPARQL only when absolutely necessary
Start by leveraging the reporting options that are easiest to adopt
To get started, consider the reporting options that require less effort to adopt:- For work-item-only reports, continue to use the data warehouse. Work items aren't versioned; as long as the report doesn't reference versioned artifacts (like requirements or tests), you can continue to use it.
- Use dashboard widgets from the applications. Most applications provide a set of configuration-aware dashboard widgets; you can also build JRS reports and add those to your dashboard.
- Generate documents. The built-in document generation continues to work, using the current configuration context. If you use Rational Publishing Engine (RPE), you can reuse existing templates by simply adding the configuration context to use. You can also build additional RPE templates and import them into the applications.
- Prioritize and build JRS reports, starting simple. Use the sample reports and the Report Builder tutorials to help get started.
Follow recommended practices for reporting in general
Observe general reporting best practices, as described in JRS Report Builder best practices. Those include scoping your queries early, instead of requesting a greal deal of data that is not really needed, and ensuring that long-running reports with large result sets appear on secondary dashboards, not the ones that are loaded frequently by many users.Use consistent type systems with external URIs
Previous topics described the importance of a [[ConsistentTypeSystem][consistent type system] using external RDF URIs to enable cross-component and cross-project linking, cloning, and copying. Those URIs are also important for reporting, making it much easier to build reports that cross components and projects. Without the URIs, you will see a separate entry for the attribute in each individual project or component, which complicates selecting attributes as well as setting conditions.For reusable reports, avoid limiting scope
In Report Builder, you can choose to limit your scope to specific project areas. When you select a project area, the options that you see for artifact types, conditions, and so on, are also limited to what is defined in that project area. Those types, attributes, and conditions might not be valid for other project areas. If you want to build a report that can be run by multiple projects, avoid limiting scope, so you see the representation across all the project areas. Defining external URIs, as described above, also makes it easier to write reports that can apply across project areas, because you have indicated their types and attributes are equivalent.0Use custom SPARQL only when absolutely necessary
Report Builder generates SPARQL queries to report on data from the LQE data source, as opposed to SQL for the data warehouse. As much as possible, use Report Builder interactively to build your reports. Although you can write custom SPARQL queries, limit them only to cases where you cannot achieve what you need through Report Builder. If you choose to customize a SPARQL query:- Create as much of the report as possible in Report Builder, and save a copy. Then edit the SPARQL in the Advanced section and save it separately. Once you edit the SPARQL, you can't go back to the Report Builder UI, and you might lose formatting and conditions that you set with the UI.
- The LQE Administration Query page provides a way to run SPARQL queries interactively for testing.
- Optimize your SPARQL query for performance. A poorly-designed query can have significant impact on system performance. For the same reason, limit the frequency and number of users who run the query.
Planning integrations with other applications
The CLM applications support integration with other non-CLM applications; however, to integrate with configuration-management-enabled project areas, those non-CLM applications typically must provide some level of support for the OSLC Configuration Management specification, and understand how to reference versioned artifacts. (Note that test execution adapters are an exception; if they integrate with RQM using the published API, RQM manages the configuration context and the adapter does not require any special support.) Identify the applications with which you plan to integrate, and check with the application provider to determine their support for configuration management. If the application does not support integrating with configuration-management-enabled projects, consider potential workarounds such as import and export. There are also a few points to consider with respect to integrations between the CLM applications:- If RM or QM project areas are linked, you must enable configuration management in both or neither. Otherwise, links between them will not work correctly.
- RTC plans and work items are not versioned, and therefore are not part of a configuration. However, you can associate plans and work items to a global configuration using the Release and link mapping mechanisms. See the Knowledge Center and this short video for details on those mechanisms.
Defining roles, permissions, and other process elements
Adopting configuration management also entails some changes to your organization's definition of roles and the associated permissions in the various applications. Ensure that you understand and assign the appropriate responsibilities in both the process and the tools. Also consider additional process elements, such as enabling link validity.Define and assign roles and permissions related to configuration management
There are additional roles associated with managing components and configurations. In some cases, roles are related to specific permissions in the applications; in others, they are defined by your process and organization. Determine who will have responsibility and permissions to:- Define and maintain your component and stream strategy from an architectural perspective
- Manage components, streams, and baselines - at the global level and for the individual applications
- Each application has permissions related to creating, modifying, and archiving components and configurations
- If your global configuration manager will use the GCM automation to create streams and baselines in the local applications, s/he needs permission in the local application as well
- Manage personal streams in the GCM application
- Create and deliver change sets, including delivery for others
- Applications that support change sets provide related permissions
- Approve change set delivery (if you mandate linking change sets to approved change requests)
- Deliver or merge changes across streams
- Define tags and attributes for the GCM application
- Define RDF URIs for common or equivalent types, attributes, and values
- Build and manage reports
Enable link validity
As part of managing change, enable link validity in your project or component properties and define how you want to use it (for example, who should set the link to valid and at what point). Use the comment capability to convey more information about the reason a link became invalid.Related topics:
- Deployment planning and design, including topologies, sizing, and performance information
- Welcome to configuration management article
- Configuration Management FAQ
- Jazz Reporting Service wiki


| I | Attachment |
Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
multi-stream.gif | manage | 33.6 K | 2017-04-04 - 19:23 | UnknownUser | main-integration-projects stream strategy diagram |
| |
single-stream.gif | manage | 6.6 K | 2017-04-04 - 19:22 | UnknownUser | single stream strategy diagram |
{kind=link}
{kind=link}
-
 Deployment web
Deployment web
-
 Planning and design
Planning and design
- Installing and upgrading
- Migrating and evolving
- Integrating
- Administering
- Monitoring
- Troubleshooting
- To do
-
 Under construction
Under construction
-
 New
New
-
 Updated
Updated
-
 Constant change
Constant change
- None - stable page
- Smaller versions of status icons for inline text:
-





Contributions are governed by our Terms of Use. Please read the following disclaimer.
Dashboards and work items are no longer publicly available, so some links may be invalid. We now provide similar information through other means. Learn more here.